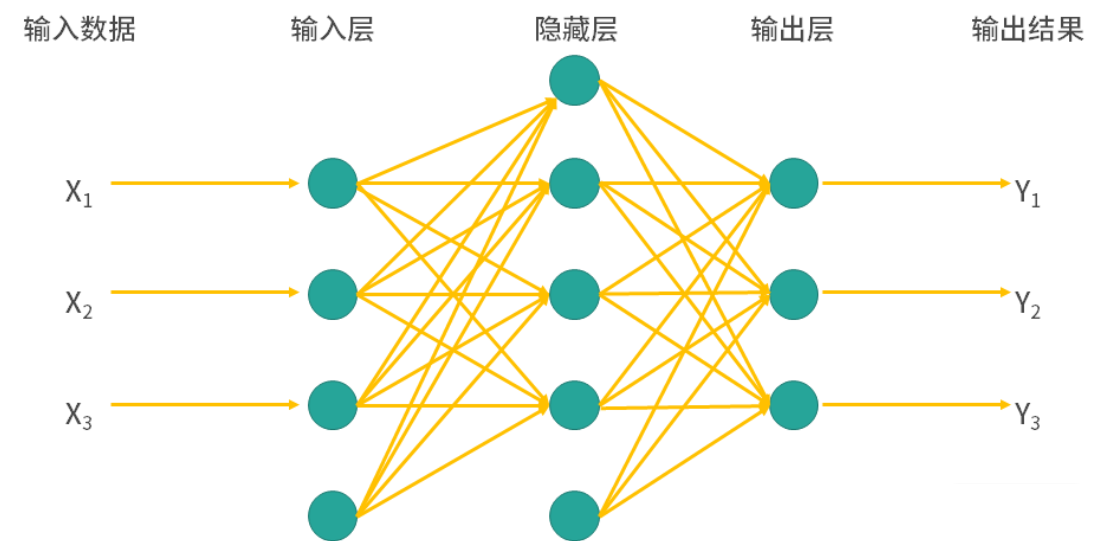
神经网络模型在人类的大脑中,神经元(neuron)是负责信息传递和处理的单元,神经元通过化学信号和电信号进行交流,这是人类记忆、感觉、运动等功能的基础。神经元包含了轴突(axon)和树突(dendrite),树突负责接收信号,轴突负责发送信号,此外细胞体也是神经元的重要部分,起到整合和传递信息的作用。神经元之间的连接通过突触(synapse)传递化学信号或电信号来实现,一个神经元可能会与成千上万个神经元连接,构成错综复杂的神经网络。人在刚出生时,大脑中有约 860 亿神经元,大部分神经元是不会再生的,所以这个数字会随着年龄的增长而略为减少。新生儿的大脑拥有数量极其庞大的突触连接,为未来的学习和适应奠定基础。很多科普文章都宣传神经网络模型是模拟人脑神经元的计算模型,通过多层神经元连接来完成复杂的非线性映射,但是没有证据表明大脑的学习机制与神经网络模型机制相同。虽然神经网络这个术语来自于神经生
集成学习算法之前的章节,我们主要为大家介绍了机器学习中的单模型。事实上,将多个单模型组合成一个综合模型的方式早已成为现代机器学习模型采用的主流方法,这种方法被称为集成学习(ensemble learning)。集成学习的目标是通过多个弱学习器(分类效果略优于随机猜测的模型,如果太强容易导致过拟合)的组合来构建强学习器,从而克服单一模型可能存在的局限性,获得比单一模型更好的泛化能力,通常用于需要高精度预测的场景。算法分类集成学习算法主要分为以下几类:Bagging:通过从训练数据中随机抽样生成多个数据子集,在这些子集上训练多个模型,并将它们的结果进行结合。这种集成学习的原理如下图所示,最典型的例子就是我们之前讲过的随机森林。Boosting:通过迭代训练多个模型,在每一轮训练时,重点关注前一轮预测错误的样本。每个新模型的训练目标是弥补前一轮模型的不足。这种集成学习的原理如下图所示,经典的算法
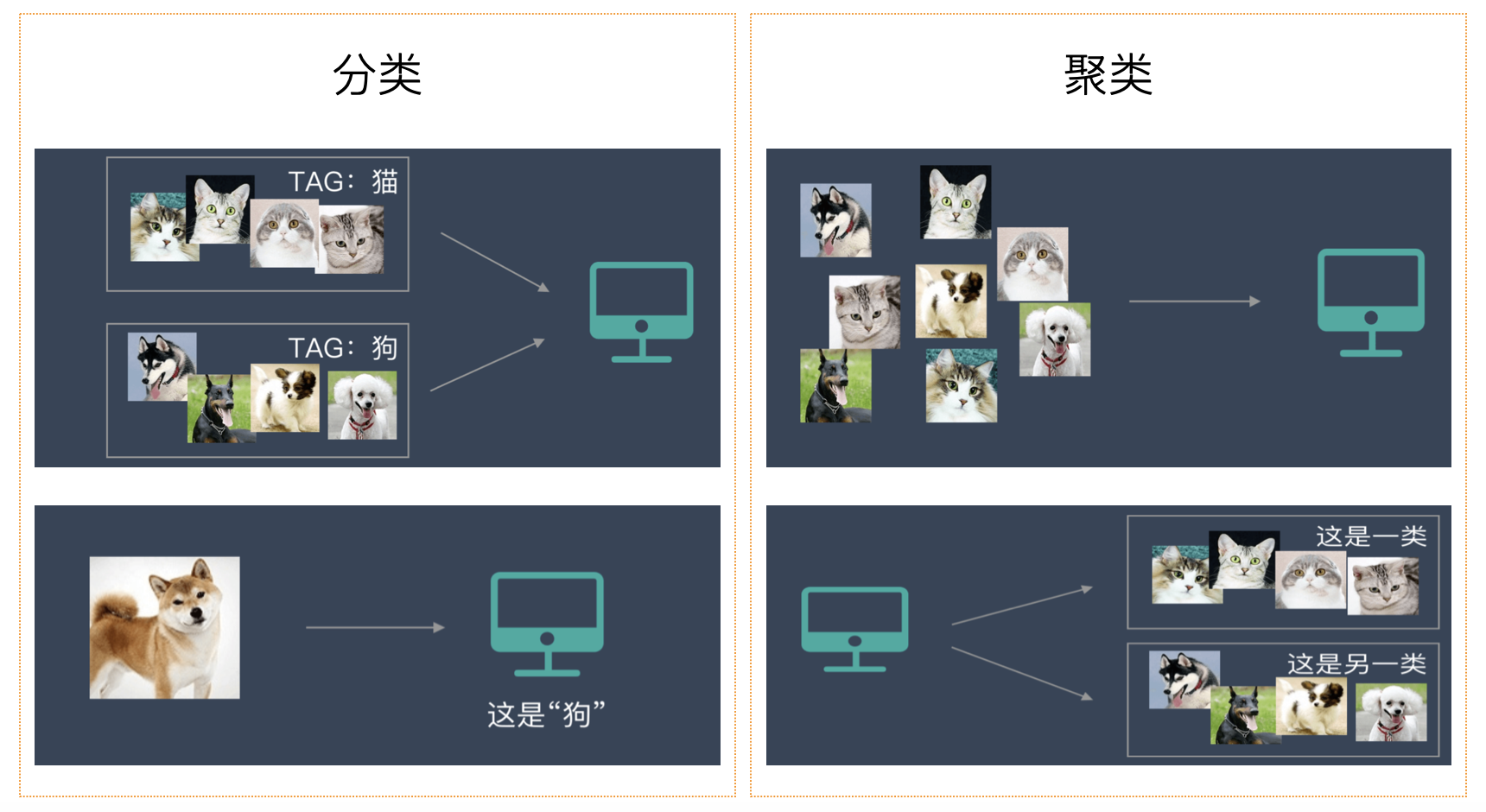
K-Means聚类算法聚类(Clustering)是数据挖掘和机器学习中的一种重要技术,用于将数据集中的样本划分为多个相似的组或类别。这种方法在许多领域得到了广泛应用,例如:电商行业:根据用户行为数据,将消费者分为不同的群体(高消费用户、高活跃用户、流失风险用户、价格敏感用户等)以制定有针对性的运营策略,实现更精准的广告投放,代表性的企业包括阿里巴巴、亚马逊(Amazon)等。金融行业:各大银行通过聚类算法分析用户的信用记录、收入水平、消费行为等数据,将用户分为不同的风险群体,对于高风险群体需要更严格的信用审核,而低风险群体可以享受更优惠的贷款利率或信用额度。医疗行业:通过分析患者的健康数据(如病史、基因数据、生活习惯等),将患者分为不同健康风险群体,提高疾病预测的准确性,推动了精准医疗的发展,代表性的公司如强生(Johnson & Johnson)、辉瑞(Pfizer)等。社交媒
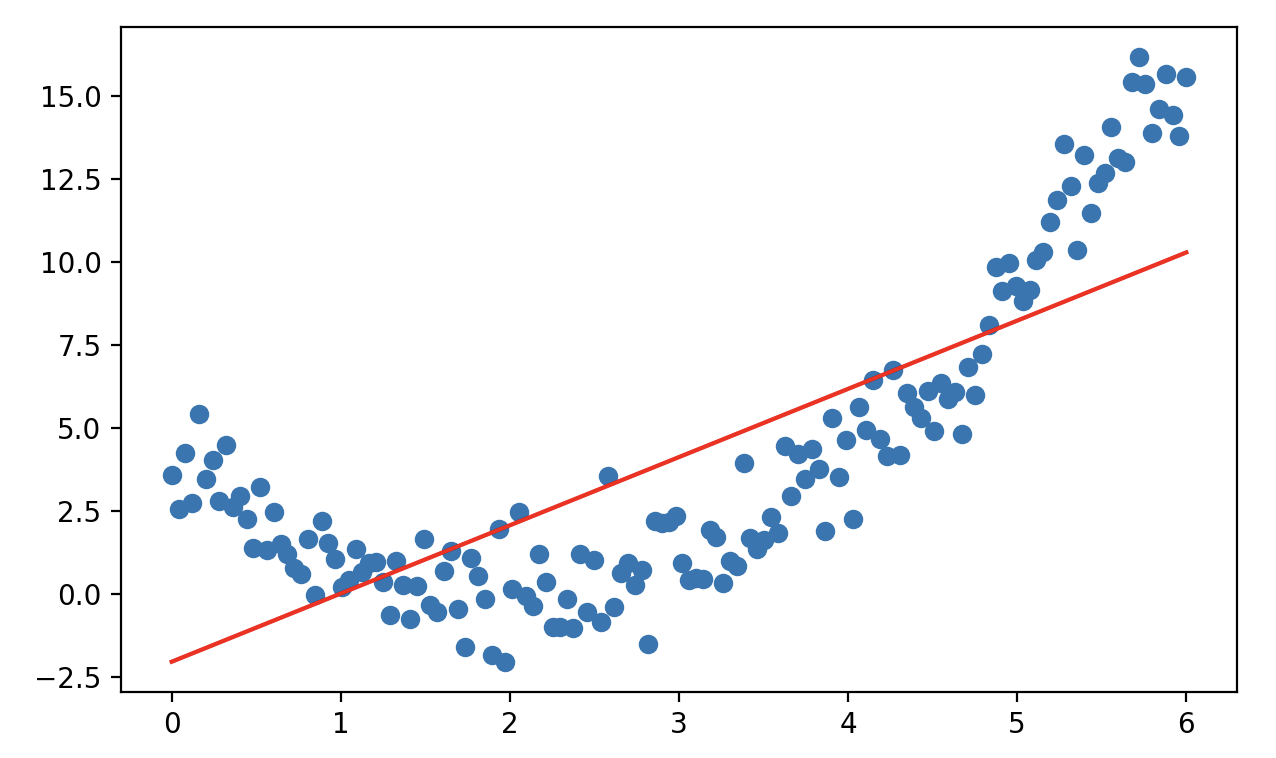
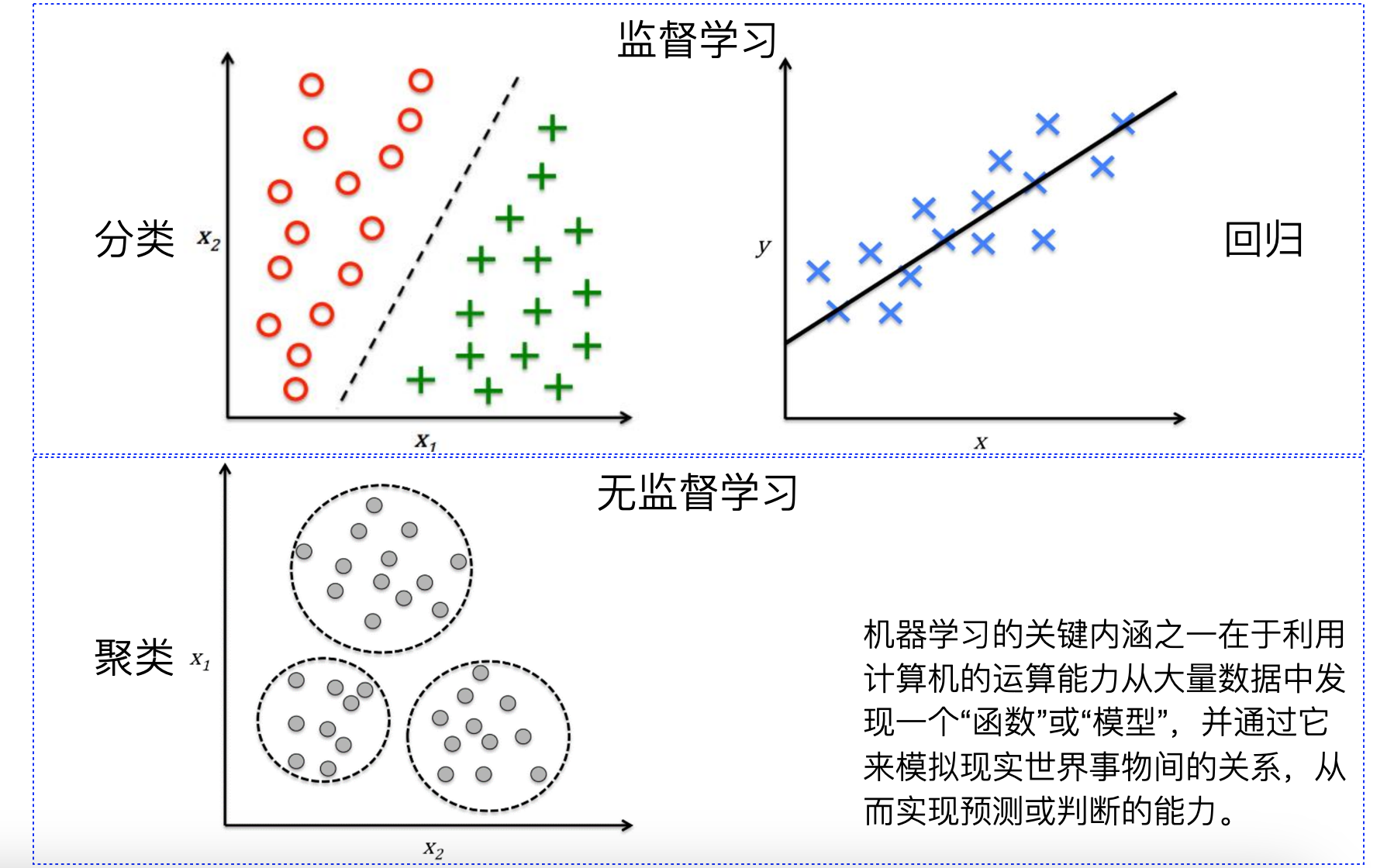
回归模型回归模型是机器学习和统计学中的一种基本模型,用于预测连续型输出变量。简单的说,给定一组输入变量(自变量)和对应的输出变量(因变量),回归模型旨在找到输入变量和输出变量之间的映射关系。回归模型的形式可能比较简单,但它确包含了机器学习中最主要的建模思想。通常,我们建立回归模型主要有两个目标:描述数据之间的关系。我们之前讲过机器学习的关键就是要通过历史数据掌握如何从特征映射到目标值,这个过程不需要我们事先设置任何的规则,而是让机器通过对历史数据的学习来获得。回归模型可以帮助我们通过模型表达输入和输出之间的关系。对未知数据做出预测。通过学习到的映射关系,模型可以对新的输入数据进行预测。回归模型的应用非常广泛,我们为大家举几个具体的例子:零售行业。全球最大的电商平台亚马逊(Amazon)会根据历史销量、商品属性(价格、折扣、品牌、类别等)、时间特征(季节、工作日、节假日等)、外部因素(天气、
朴素贝叶斯算法我们继续为大家介绍解决分类任务的算法,本章介绍一种概率模型贝叶斯分类器。贝叶斯分类器是一类分类算法的总称,这类算法均以贝叶斯定理为基础,因而统称为贝叶斯分类器。在介绍贝叶斯定理之前,我们先讲一个故事:从 2015 年到 2020 年期间,某位李姓女士凭借自己对航班是否会延误的分析,购买了大约 900 次飞机延误险并获得延误赔偿,累计获得理赔金高达 300 多万元,真可谓“航班延误,发家致富”。当然,这套骚操作本身不是我们探讨的重点,我们的问题是:李女士是怎么决定要不要购买延误险的呢?航班延误最主要的原因就是天气(包括起飞地和降落地的天气)、机场(起飞机场和降落机场)和航司,由于李女士有过航空服务类工作的经历,有获得机场和航司相关数据的途径(天气数据相对更容易获取),集齐相关的数据再利用贝叶斯定理,她可以能够计算出当前航班延误的概率并决定是否购买延误险。接下来,李女士通过虚构不
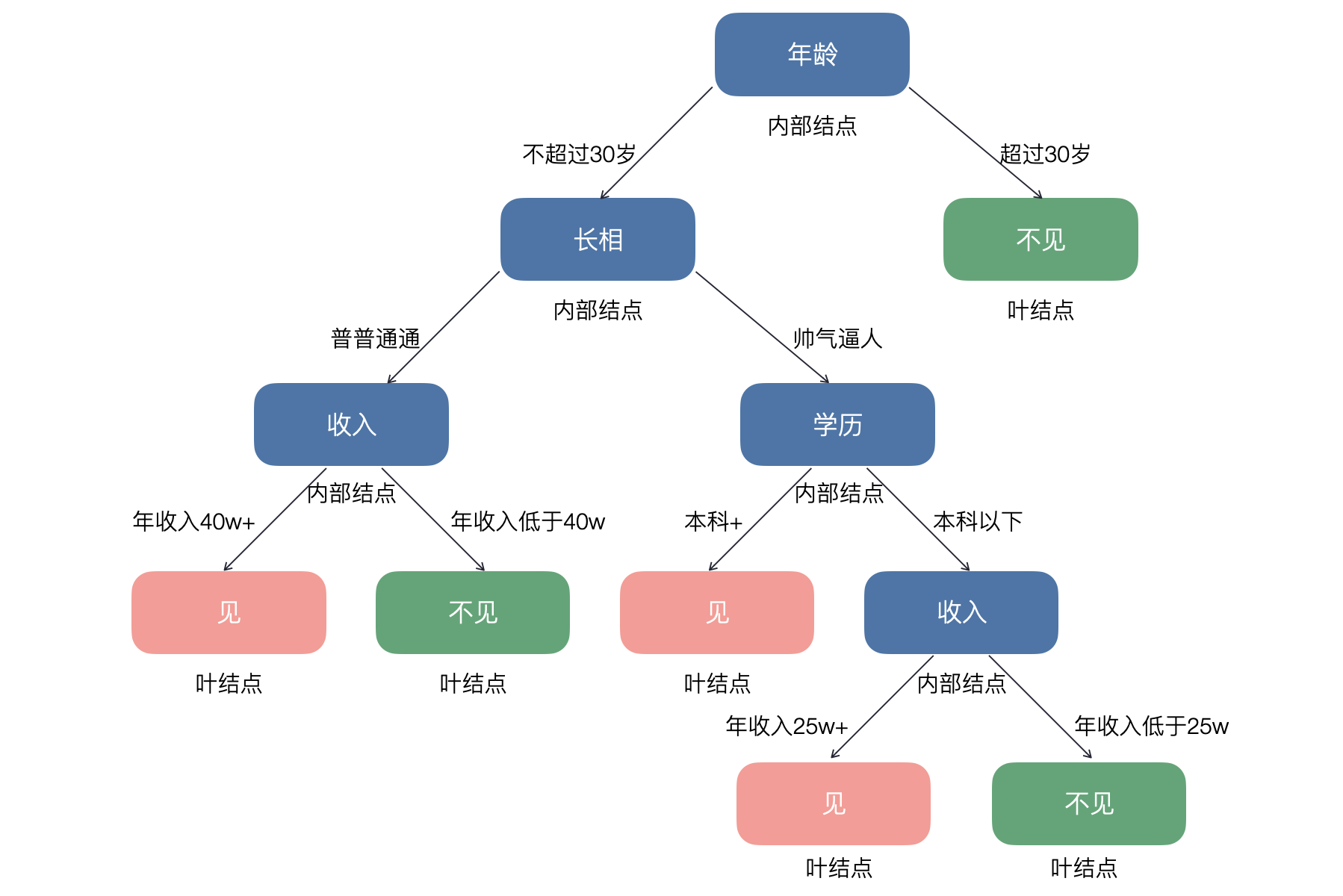
决策树和随机森林决策树(Decision Tree)是一种基于树结构的监督学习算法,可用于分类和回归任务。它通过将数据集逐步分割成不同的子集,直到满足某些停止条件,以此实现预测目标。我们生活中做决策的时候也会用到类似的方法,例如某位女生约见相亲对象的决策方法就可以绘制成如下所示的决策树。说明:上图仅用于帮助大家理解什么是决策树,无不良引导,也不代表本人的爱情观和婚姻观。如果具备一定的编程常识,你会发现用决策树做预测的过程相当于是执行了一系列的if...else...结构;如果你对概率论的知识更熟悉,那么决策树的构建也可以视为计算以特征空间为前提的条件概率的过程。决策树中的结点可以分为两类:内部结点(上图中蓝色的结点)和叶结点(上图中红色和绿色的结点),其中内部结点对应样本特征属性测试(特征分割条件),而叶结点代表决策的结果(分类标签或回归目标值)。决策树可以用于解决分类问题和回归问题,本章
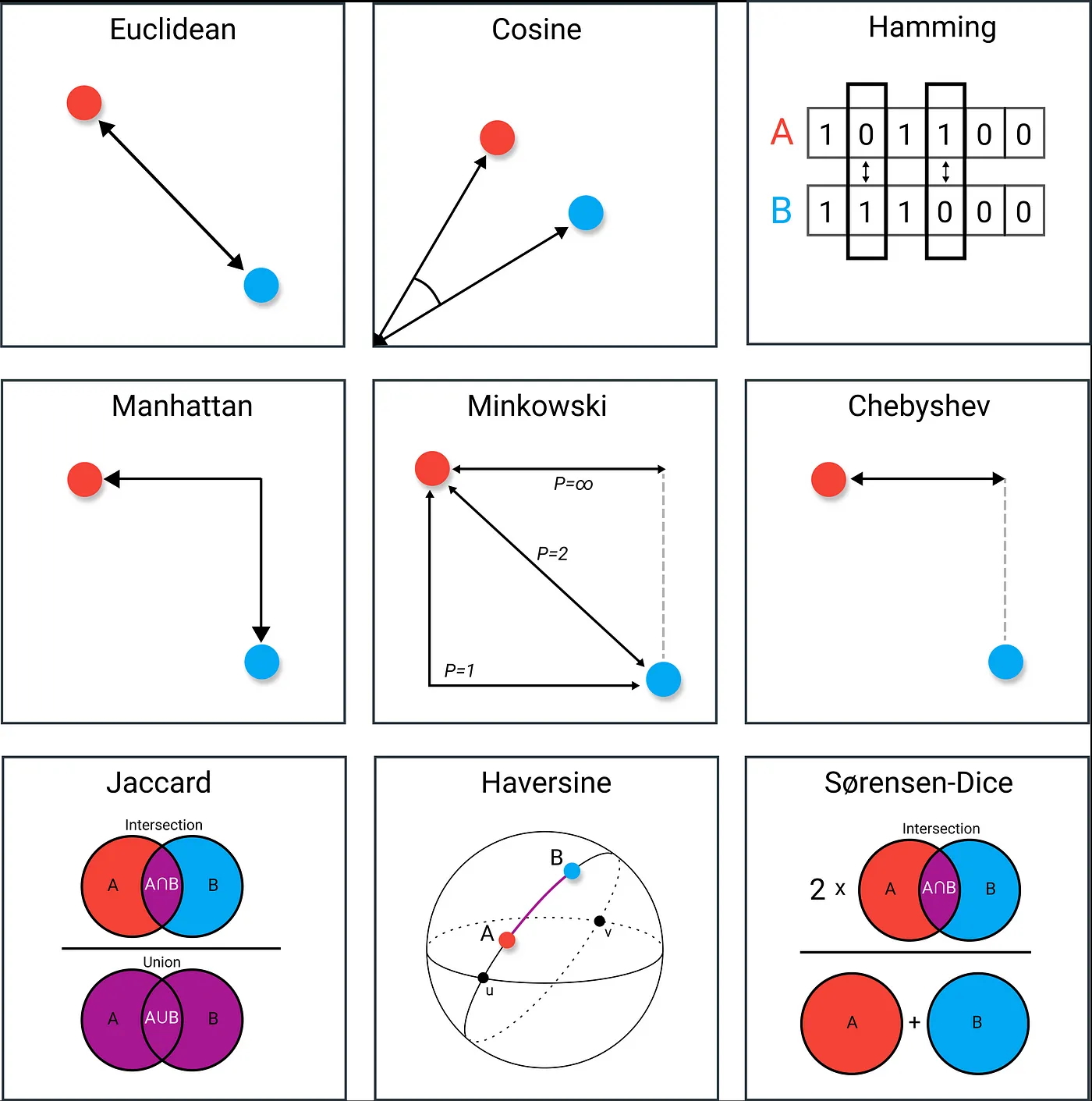
k最近邻算法k 最近邻算法(kNN)是一种用于分类和回归的非参数统计方法,由美国统计学家伊芙琳·费克斯和小约瑟夫·霍奇斯于 1951 年提出。kNN 算法的原理是从历史数据中找到 个跟新输入的实例最邻近的实例,根据它们中的多数所属的类别来对新实例进行分类或者输出新实例的目标值,这种算法我们在前面已经为大家做了简单的展示。与主流的机器学习算法不同,k 最近邻算法没有显式的学习训练过程,它用的是“近朱者赤,近墨者黑”这样一种简单朴素的思想来实现分类或回归。k 最近邻算法有两个关键问题,第一个是 $\small{k}$ 值如何选择,即用多少个最近邻来判定新实例所属的类别或确定其目标值;第二个是如何判定两个实例是近还是远,这里就涉及到度量距离的问题。距离的度量我们可以用距离(distance)来衡量特征空间中两个实例之间的相似度,常用的距离度量包括闵氏距离、马氏距离、余弦距离、编辑距离等。闵氏距
浅谈机器学习人工智能无疑是最近几年热度极高的一个词,从2016年谷歌 DeepMind 团队开发的 AlphaGo 围棋程序战胜人类顶尖棋手,到2017年基于 Transformer 架构的 NLP 模型发布,再到2023年 OpenAI 推出基于 GPT-4 的 ChatGPT 以及人工智能在医疗、自动驾驶等领域的深度应用,人工智能的热潮到达了自1956年达特茅斯会议以来前所未有的高度,可以说几乎每个人的生活都或多或少的受到了人工智能的影响。人工智能是计算机科学的一个重要分支,涉及计算机模拟智能行为的能力以及机器模仿人类智能行为的能力。研究人工智能的主要目标是开发出能够独立做出决策的系统,从而在医疗、工程、金融、教育、科研、公共服务等诸多领域帮助人类更高效的工作。人工智能的英文是“artificial intelligence”,因此通常被简称为 AI,人工智能包含了诸多的内容,我们经常

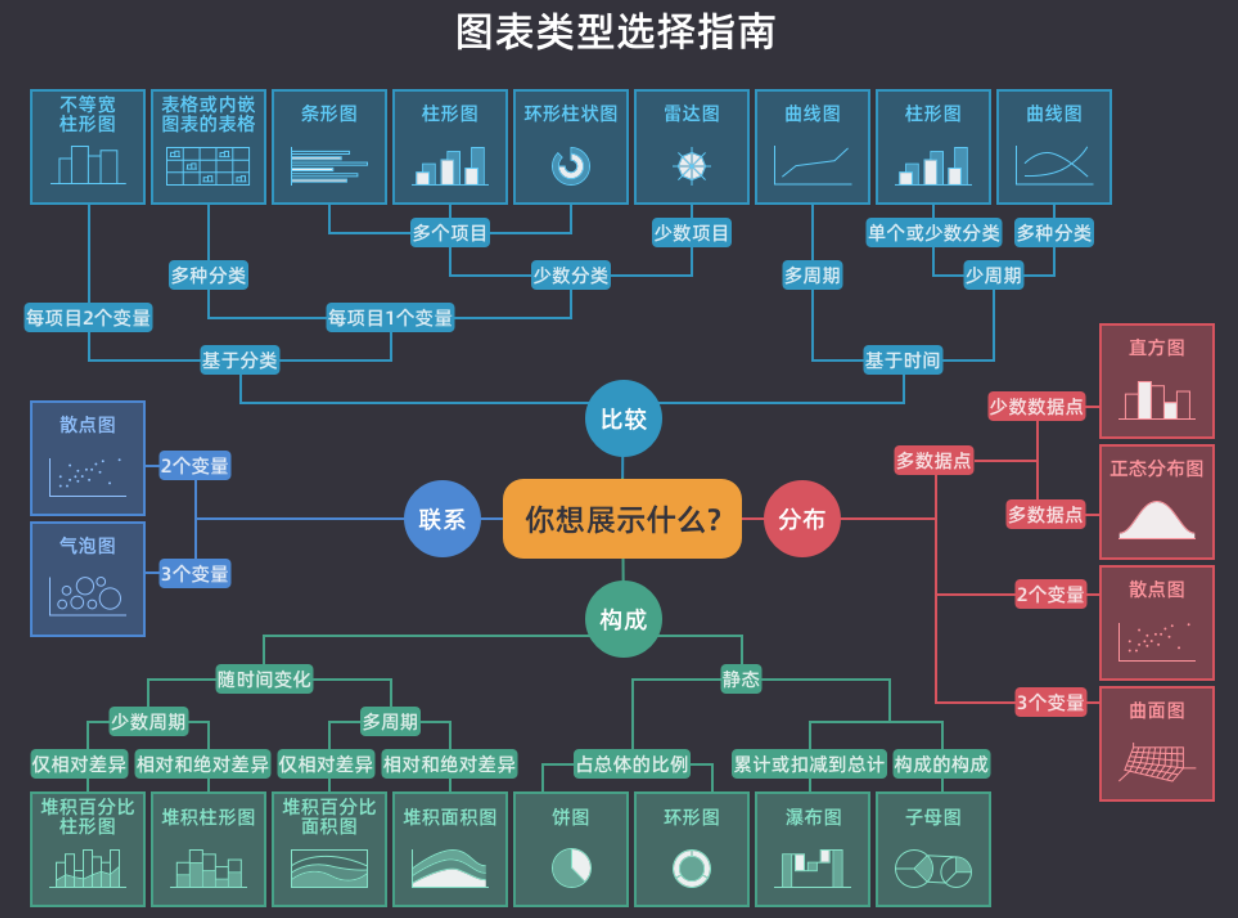
数据可视化在完成了对数据的透视之后,我们可以将数据透视的结果通过可视化的方式呈现出来,简单的说,就是将数据变成漂亮的统计图表,因为人类对颜色和形状会更加敏感,然后再进一步解读数据背后隐藏的商业价值。在之前的课程中,我们已经为大家展示过用使用Series或DataFrame对象的plot方法生成可视化图表的操作,本章我们为大家讲解这个绘图方法的基石,它就是大名鼎鼎的 matplotlib 库。在讲解 matplotlib 之前,请大家先看看下面这张图,它给出了常用的图表类型及其应用场景。我们在选择统计图表时,如果不知道做出怎样的选择最合适,相信这张图就能帮到你。简单的说,看趋势折线图,比数据柱状图,定关系散点图,查占比饼状图,看分布直方图,找离群箱线图。导入和配置之前的课程中,我们为大家讲解过如何安装和导入 matplotlib 库,如果不确定是否已经安装了 matplotlib,可以使用下
深入浅出pandas-1Pandas 是 Wes McKinney 在2008年开发的一个强大的分析结构化数据的工具集。Pandas 以 NumPy 为基础(实现数据存储和运算),提供了专门用于数据分析的类型、方法和函数,对数据分析和数据挖掘提供了很好的支持;同时 pandas 还可以跟数据可视化工具 matplotlib 很好的整合在一起,非常轻松愉快的实现数据可视化呈现。Pandas 核心的数据类型是Series(数据系列)、DataFrame(数据窗/数据框),分别用于处理一维和二维的数据,除此之外,还有一个名为Index的类型及其子类型,它们为Series和DataFrame提供了索引功能。日常工作中DataFrame使用得最为广泛,因为二维的数据结构刚好可以对应有行有列的表格。Series和DataFrame都提供了大量的处理数据的方法,数据分析师以此为基础,可以实现对数据的筛选