深入浅出pandas-1Pandas 是 Wes McKinney 在2008年开发的一个强大的分析结构化数据的工具集。Pandas 以 NumPy 为基础(实现数据存储和运算),提供了专门用于数据分析的类型、方法和函数,对数据分析和数据挖掘提供了很好的支持;同时 pandas 还可以跟数据可视化工具 matplotlib 很好的整合在一起,非常轻松愉快的实现数据可视化呈现。Pandas 核心的数据类型是Series(数据系列)、DataFrame(数据窗/数据框),分别用于处理一维和二维的数据,除此之外,还有一个名为Index的类型及其子类型,它们为Series和DataFrame提供了索引功能。日常工作中DataFrame使用得最为广泛,因为二维的数据结构刚好可以对应有行有列的表格。Series和DataFrame都提供了大量的处理数据的方法,数据分析师以此为基础,可以实现对数据的筛选

Pandas 是 Wes McKinney 在2008年开发的一个强大的分析结构化数据的工具集。Pandas 以 NumPy 为基础(实现数据存储和运算),提供了专门用于数据分析的类型、方法和函数,对数据分析和数据挖掘提供了很好的支持;同时 pandas 还可以跟数据可视化工具 matplotlib 很好的整合在一起,非常轻松愉快的实现数据可视化呈现。
Pandas 核心的数据类型是Series(数据系列)、DataFrame(数据窗/数据框),分别用于处理一维和二维的数据,除此之外,还有一个名为Index的类型及其子类型,它们为Series和DataFrame提供了索引功能。日常工作中DataFrame使用得最为广泛,因为二维的数据结构刚好可以对应有行有列的表格。Series和DataFrame都提供了大量的处理数据的方法,数据分析师以此为基础,可以实现对数据的筛选、合并、拼接、清洗、预处理、聚合、透视和可视化等各种操作。
创建Series对象
Pandas 库中的Series对象可以用来表示一维数据结构,但是多了索引和一些额外的功能。Series类型的内部结构包含了两个数组,其中一个用来保存数据,另一个用来保存数据的索引。我们可以通过列表或数组创建Series对象,代码如下所示。
代码:
import numpy as np
import pandas as pd
ser1 = pd.Series(data=[120, 380, 250, 360], index=['一季度', '二季度', '三季度', '四季度'])
ser1
说明:
Series构造器中的data参数表示数据,index参数表示数据的索引,相当于数据对应的标签。
输出:
一季度 120
二季度 380
三季度 250
四季度 360
dtype: int64
通过字典创建Series对象。
代码:
ser2 = pd.Series({'一季度': 320, '二季度': 180, '三季度': 300, '四季度': 405})
ser2
说明:通过字典创建
Series对象时,字典的键就是数据的标签(索引),键对应的值就是数据。
输出:
一季度 320
二季度 180
三季度 300
四季度 405
dtype: int64
Series对象的运算
标量运算
我们尝试给刚才的ser1每个季度加上10,代码如下所示。
代码:
ser1 += 10
ser1
输出:
一季度 130
二季度 390
三季度 260
四季度 370
dtype: int64
矢量运算
我们尝试把ser1和ser2对应季度的数据加起来,代码如下所示。
代码:
ser1 + ser2
输出:
一季度 450
二季度 570
三季度 560
四季度 775
dtype: int64
索引运算
普通索引
跟数组一样,Series对象也可以进行索引和切片操作,不同的是Series对象因为内部维护了一个保存索引的数组,所以除了可以使用整数索引检索数据外,还可以通过自己设置的索引(标签)获取对应的数据。
使用整数索引。
代码:
ser1[2]
输出:
260
使用自定义索引。
代码:
ser1['三季度']
输出:
260
代码:
ser1['一季度'] = 380
ser1
输出:
一季度 380
二季度 390
三季度 260
四季度 370
dtype: int64
切片索引
Series对象的切片操作跟列表、数组类似,通过给出起始和结束索引,从原来的Series对象中取出或修改部分数据,这里也可以使用整数索引和自定义的索引,代码如下所示。
代码:
ser2[1:3]
输出:
二季度 180 三季度 300 dtype: int64
代码:
ser2['二季度':'四季度']
输出:
二季度 180
三季度 300
四季度 405
dtype: int64
提示:在使用自定义索引进行切片时,结束索引对应的元素也是可以取到的。
代码:
ser2[1:3] = 400, 500
ser2
输出:
一季度 320
二季度 400
三季度 500
四季度 405
dtype: int64
花式索引
代码:
ser2[['二季度', '四季度']]
输出:
二季度 400
四季度 405
dtype: int64
代码:
ser2[['二季度', '四季度']] = 600, 520
ser2
输出:
一季度 320
二季度 600
三季度 500
四季度 520
dtype: int64
布尔索引
代码:
ser2[ser2 >= 500]
输出:
二季度 600
三季度 500
四季度 520
dtype: int64
Series对象的属性和方法
Series对象的属性和方法非常多,我们就捡着重要的跟大家讲吧。先看看下面的表格,它展示了Series对象常用的属性。
| 属性 | 说明 |
|---|---|
dtype / dtypes | 返回Series对象的数据类型 |
hasnans | 判断Series对象中有没有空值 |
at / iat | 通过索引访问Series对象中的单个值 |
loc / iloc | 通过索引访问Series对象中的单个值或一组值 |
index | 返回Series对象的索引(Index对象) |
is_monotonic | 判断Series对象中的数据是否单调 |
is_monotonic_increasing | 判断Series对象中的数据是否单调递增 |
is_monotonic_decreasing | 判断Series对象中的数据是否单调递减 |
is_unique | 判断Series对象中的数据是否独一无二 |
size | 返回Series对象中元素的个数 |
values | 以ndarray的方式返回Series对象中的值(ndarray对象) |
我们可以通过下面的代码来了解Series对象的属性。
代码:
print(ser2.dtype) # 数据类型
print(ser2.hasnans) # 有没有空值
print(ser2.index) # 索引
print(ser2.values) # 值
print(ser2.is_monotonic_increasing) # 是否单调递增
print(ser2.is_unique) # 是否每个值都独一无二
输出:
int64
False
Index(['一季度', '二季度', '三季度', '四季度'], dtype='object')
[320 600 500 520]
False
True
Series对象的方法很多,下面我们通过一些代码片段为大家介绍常用的方法。
统计相关
Series对象支持各种获取描述性统计信息的方法。
代码:
print(ser2.count()) # 计数
print(ser2.sum()) # 求和
print(ser2.mean()) # 求平均
print(ser2.median()) # 找中位数
print(ser2.max()) # 找最大
print(ser2.min()) # 找最小
print(ser2.std()) # 求标准差
print(ser2.var()) # 求方差
输出:
4
1940
485.0
510.0
600
320
118.18065267490557
13966.666666666666
Series对象还有一个名为describe()的方法,可以获得上述所有的描述性统计信息,如下所示。
代码:
ser2.describe()
输出:
count 4.000000
mean 485.000000
std 118.180653
min 320.000000
25% 455.000000
50% 510.000000
75% 540.000000
max 600.000000
dtype: float64
提示:因为
describe()返回的也是一个Series对象,所以也可以用ser2.describe()['mean']来获取平均值,用ser2.describe()[['max', 'min']]来获取最大值和最小值。
如果Series对象有重复的值,我们可以使用unique()方法获得由独一无二的值构成的数组;可以使用nunique()方法统计不重复值的数量;如果想要统计每个值重复的次数,可以使用value_counts()方法,这个方法会返回一个Series对象,它的索引就是原来的Series对象中的值,而每个值出现的次数就是返回的Series对象中的数据,在默认情况下会按照出现次数做降序排列,如下所示。
代码:
ser3 = pd.Series(data=['apple', 'banana', 'apple', 'pitaya', 'apple', 'pitaya', 'durian'])
ser3.value_counts()
输出:
apple 3
pitaya 2
durian 1
banana 1
dtype: int64
代码:
ser3.nunique()
输出:
4
对于ser3,我们还可以用mode()方法来找出数据的众数,由于众数可能不唯一,所以mode()方法的返回值仍然是一个Series对象。
代码:
ser3.mode()
输出:
0 apple
dtype: object
处理数据
Series对象的isna()和isnull()方法可以用于空值的判断,notna()和notnull()方法可以用于非空值的判断,代码如下所示。
代码:
ser4 = pd.Series(data=[10, 20, np.nan, 30, np.nan])
ser4.isna()
说明:
np.nan是一个IEEE 754标准的浮点小数,专门用来表示“不是一个数”,在上面的代码中我们用它来代表空值;当然,也可以用 Python 中的None来表示空值,在 pandas 中None也会被处理为np.nan。
输出:
0 False
1 False
2 True
3 False
4 True
dtype: bool
代码:
ser4.notna()
输出:
0 True
1 True
2 False
3 True
4 False
dtype: bool
Series对象的dropna()和fillna()方法分别用来删除空值和填充空值,具体的用法如下所示。
代码:
ser4.dropna()
输出:
0 10.0
1 20.0
3 30.0
dtype: float64
代码:
ser4.fillna(value=40) # 将空值填充为40
输出:
0 10.0
1 20.0
2 40.0
3 30.0
4 40.0
dtype: float64
代码:
ser4.fillna(method='ffill') # 用空值前面的非空值填充
输出:
0 10.0
1 20.0
2 20.0
3 30.0
4 30.0
dtype: float64
需要提醒大家注意的是,dropna()和fillna()方法都有一个名为inplace的参数,它的默认值是False,表示删除空值或填充空值不会修改原来的Series对象,而是返回一个新的Series对象。如果将inplace参数的值修改为True,那么删除或填充空值会就地操作,直接修改原来的Series对象,此时方法的返回值是None。后面我们会接触到的很多方法,包括DataFrame对象的很多方法都会有这个参数,它们的意义跟这里是一样的。
Series对象的mask()和where()方法可以将满足或不满足条件的值进行替换,如下所示。
代码:
ser5 = pd.Series(range(5))
ser5.where(ser5 > 0)
输出:
0 NaN
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64
代码:
ser5.where(ser5 > 1, 10)
输出:
0 10
1 10
2 2
3 3
4 4
dtype: int64
代码:
ser5.mask(ser5 > 1, 10)
输出:
0 0
1 1
2 10
3 10
4 10
dtype: int64
Series对象的duplicated()方法可以帮助我们找出重复的数据,而drop_duplicates()方法可以帮我们删除重复数据。
代码:
ser3.duplicated()
输出:
0 False
1 False
2 True
3 False
4 True
5 True
6 False
dtype: bool
代码:
ser3.drop_duplicates()
输出:
0 apple
1 banana
3 pitaya
6 durian
dtype: object
Series对象的apply()和map()方法非常重要,它们可以通过字典或者指定的函数来处理数据,把数据映射或转换成我们想要的样子。这两个方法在数据准备阶段非常重要,我们先来试一试这个名为map的方法。
代码:
ser6 = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
ser6
输出:
0 cat
1 dog
2 NaN
3 rabbit
dtype: object
代码:
ser6.map({'cat': 'kitten', 'dog': 'puppy'})说明:通过字典给出的映射规则对数据进行处理。
输出:
0 kitten
1 puppy
2 NaN
3 NaN
dtype: object
代码:
ser6.map('I am a {}'.format, na_action='ignore')说明:将指定字符串的
format方法作用到数据系列的数据上,忽略掉所有的空值。
输出:
0 I am a cat
1 I am a dog
2 NaN
3 I am a rabbit
dtype: object
我们创建一个新的Series对象,
ser7 = pd.Series([20, 21, 12], index=['London', 'New York', 'Helsinki'])
ser7
输出:
London 20
New York 21
Helsinki 12
dtype: int64
代码:
ser7.apply(np.square)
说明:将求平方的函数作用到数据系列的数据上,也可以将参数
np.square替换为lambda x: x ** 2。
输出:
London 400
New York 441
Helsinki 144
dtype: int64
代码:
ser7.apply(lambda x, value: x - value, args=(5, ))
注意:上面
apply方法中的lambda函数有两个参数,第一个参数是数据系列中的数据,而第二个参数需要我们传入,所以我们给apply方法增加了args参数,用于给lambda函数的第二个参数传值。
输出:
London 15
New York 16
Helsinki 7
dtype: int64
取头部值和排序
Series对象的sort_index()和sort_values()方法可以用于对索引和数据的排序,排序方法有一个名为ascending的布尔类型参数,该参数用于控制排序的结果是升序还是降序;而名为kind的参数则用来控制排序使用的算法,默认使用了quicksort,也可以选择mergesort或heapsort;如果存在空值,那么可以用na_position参数空值放在最前还是最后,默认是last,代码如下所示。
代码:
ser8 = pd.Series(
data=[35, 96, 12, 57, 25, 89],
index=['grape', 'banana', 'pitaya', 'apple', 'peach', 'orange']
)
ser8.sort_values() # 按值从小到大排序
输出:
pitaya 12
peach 25
grape 35
apple 57
orange 89
banana 96
dtype: int64
代码:
ser8.sort_index(ascending=False) # 按索引从大到小排序
输出:
pitaya 12
peach 25
orange 89
grape 35
banana 96
apple 57
dtype: int64
如果要从Series对象中找出元素中最大或最小的“Top-N”,我们不需要对所有的值进行排序的,可以使用nlargest()和nsmallest()方法来完成,如下所示。
代码:
ser8.nlargest(3) # 值最大的3个
输出:
banana 96
orange 89
apple 57
dtype: int64
代码:
ser8.nsmallest(2) # 值最小的2个
输出:
pitaya 12
peach 25
dtype: int64
绘制图表
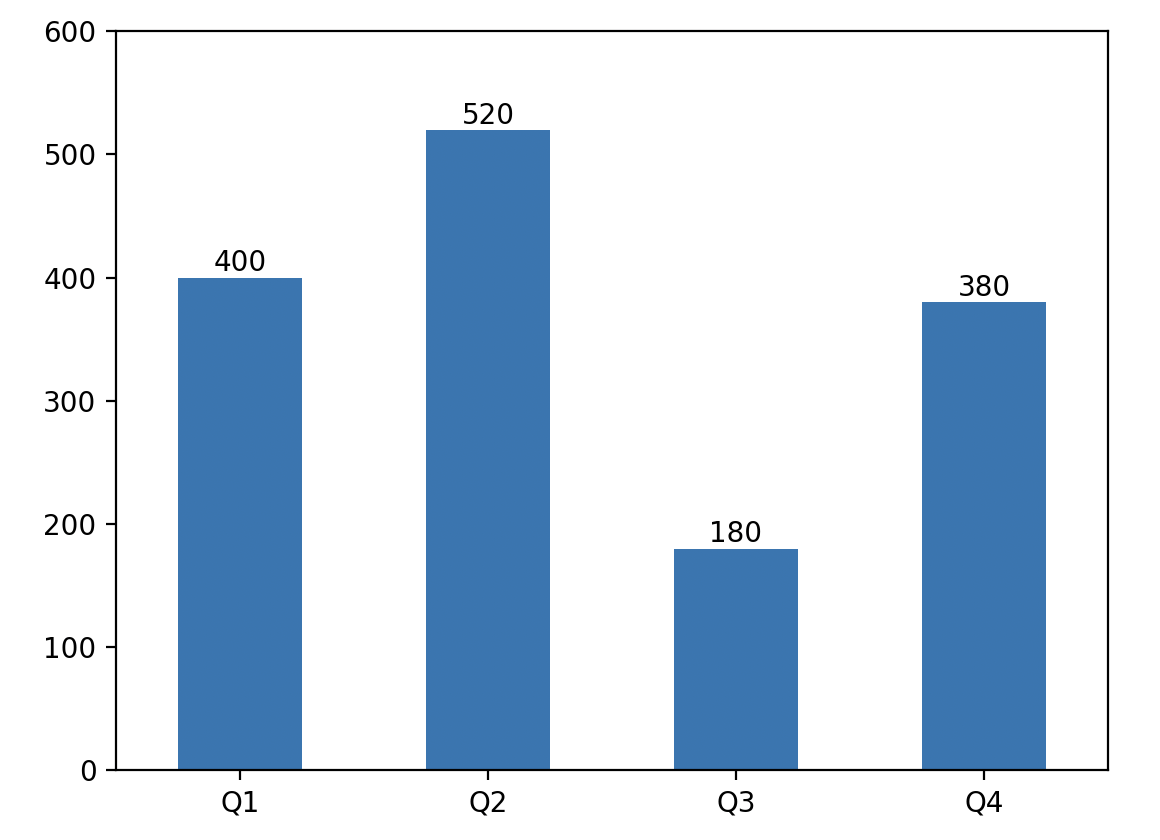
Series对象有一个名为plot的方法可以用来生成图表,如果选择生成折线图、饼图、柱状图等,默认会使用Series对象的索引作为横坐标,使用Series对象的数据作为纵坐标。下面我们创建一个Series对象并基于它绘制柱状图,代码如下所示。
代码:
import matplotlib.pyplot as plt
ser9 = pd.Series({'Q1': 400, 'Q2': 520, 'Q3': 180, 'Q4': 380})
# 通过plot方法的kind指定图表类型为柱状图
ser9.plot(kind='bar')
# 定制纵轴的取值范围
plt.ylim(0, 600)
# 定制横轴刻度(旋转到0度)
plt.xticks(rotation=0)
# 为柱子增加数据标签
for i in range(ser9.size):
plt.text(i, ser9[i] + 5, ser9[i], ha='center')
plt.show()
输出:

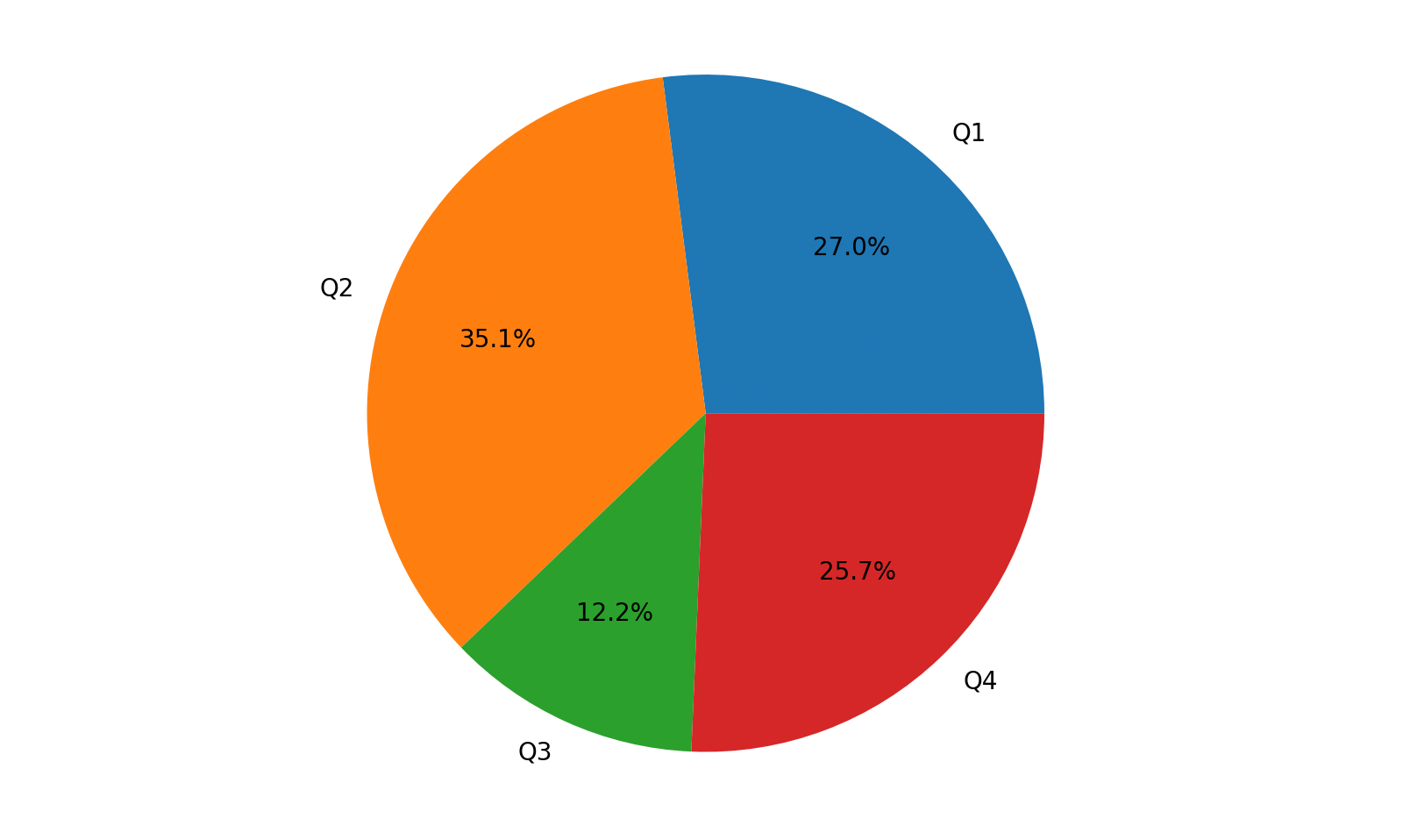
我们也可以将其绘制为饼图,代码如下所示。
代码:
# plot方法的kind参数指定了图表类型为饼图
# autopct会自动计算并显示百分比
# pctdistance用来控制百分比到圆心的距离
ser9.plot(kind='pie', autopct='%.1f%%', pctdistance=0.65)
plt.show()
输出:
如果使用 pandas 做数据分析,那么DataFrame一定是被使用得最多的类型,它可以用来保存和处理异质的二维数据。这里所谓的“异质”是指DataFrame中每个列的数据类型不需要相同,这也是它区别于 NumPy 二维数组的地方。DataFrame提供了极为丰富的属性和方法,帮助我们实现对数据的重塑、清洗、预处理、透视、呈现等一系列操作。
创建DataFrame对象
通过二维数组创建DataFrame对象
代码:
scores = np.random.randint(60, 101, (5, 3))
courses = ['语文', '数学', '英语']
stu_ids = np.arange(1001, 1006)
df1 = pd.DataFrame(data=scores, columns=courses, index=stu_ids)
df1
输出:
语文 数学 英语
1001 69 80 79
1002 71 60 100
1003 94 81 93
1004 88 88 67
1005 82 66 60
通过字典创建DataFrame对象
代码:
scores = {
'语文': [62, 72, 93, 88, 93],
'数学': [95, 65, 86, 66, 87],
'英语': [66, 75, 82, 69, 82],
}
stu_ids = np.arange(1001, 1006)
df2 = pd.DataFrame(data=scores, index=stu_ids)
df2
输出:
语文 数学 英语
1001 62 95 66
1002 72 65 75
1003 93 86 82
1004 88 66 69
1005 93 87 82
读取CSV文件创建DataFrame对象
可以通过pandas 模块的read_csv函数来读取 CSV 文件,read_csv函数的参数非常多,下面介绍几个比较重要的参数。
sep/delimiter:分隔符,默认是,。header:表头(列索引)的位置,默认值是infer,用第一行的内容作为表头(列索引)。index_col:用作行索引(标签)的列。usecols:需要加载的列,可以使用序号或者列名。true_values/false_values:哪些值被视为布尔值True/False。skiprows:通过行号、索引或函数指定需要跳过的行。skipfooter:要跳过的末尾行数。nrows:需要读取的行数。na_values:哪些值被视为空值。iterator:设置为True,函数返回迭代器对象。chunksize:配合上面的参数,设置每次迭代获取的数据体量。
代码:
df3 = pd.read_csv('data/2018年北京积分落户数据.csv', index_col='id')
df3
提示:上面代码中的CSV文件是用相对路径进行获取的,也就是说当前工作路径下有名为
data的文件夹,而“2018年北京积分落户数据.csv”就在这个文件夹下。如果使用Windows系统,在写路径分隔符时也建议使用/而不是\,如果想使用\,建议在字符串前面添加一个r,使用原始字符串来避开转义字符,例如r'c:\new\data\2018年北京积分落户数据.csv'。
输出:
name birthday company score
id
1 杨xx 1972-12 北京利德华福xxxx 122.59
2 纪xx 1974-12 北京航天数据xxxx 121.25
3 王x 1974-05 品牌联盟(北京)xx 118.96
4 杨x 1975-07 中科专利商标xxxx 118.21
5 张xx 1974-11 北京阿里巴巴xxxx 117.79
... ... ... ... ...
6015 孙xx 1978-08 华为海洋网络xxxx 90.75
6016 刘xx 1976-11 福斯(上海)xxxx 90.75
6017 周x 1977-10 赢创德固赛xxxxxx 90.75
6018 赵x 1979-07 澳科利耳医疗xxxx 90.75
6019 贺x 1981-06 北京宝洁技术xxxx 90.75
[6019 rows x 4 columns]
说明: 上面输出的内容隐去了姓名(name)和公司名称(company)字段中的部分信息。如果需要上面例子中的 CSV 文件,可以通过百度云盘获取,链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g,提取码:e7b4。
读取Excel工作表创建DataFrame对象
可以通过pandas 模块的read_excel函数来读取 Excel 文件,该函数与上面的read_csv非常类似,多了一个sheet_name参数来指定数据表的名称,但是不同于 CSV 文件,没有sep或delimiter这样的参数。假设有名为“2022年股票数据.xlsx”的 Excel 文件,里面有用股票代码命名的五个表单,分别是阿里巴巴(BABA)、百度(BIDU)、京东(JD)、亚马逊(AMZN)、甲骨文(ORCL)这五个公司2022年的股票数据,如果想加载亚马逊的股票数据,代码如下所示。
代码:
df4 = pd.read_excel('data/2022年股票数据.xlsx', sheet_name='AMZN', index_col='Date')
df4
说明:上面例子中的 CSV 文件可以通过百度云盘获取,链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g,提取码:e7b4。
输出:
Open High Low Close Volume
Date
2022-12-30 83.120 84.050 82.4700 84.000 62401194
2022-12-29 82.870 84.550 82.5500 84.180 54995895
2022-12-28 82.800 83.480 81.6900 81.820 58228575
2022-12-27 84.970 85.350 83.0000 83.040 57284035
2022-12-23 83.250 85.780 82.9344 85.250 57433655
... ... ... ... ... ...
2022-01-07 163.839 165.243 162.0310 162.554 46605900
2022-01-06 163.450 164.800 161.9370 163.254 51957780
2022-01-05 166.883 167.126 164.3570 164.357 64302720
2022-01-04 170.438 171.400 166.3490 167.522 70725160
2022-01-03 167.550 170.704 166.1600 170.404 63869140
[251 rows x 5 columns]
读取关系数据库二维表创建DataFrame对象
pandas模块的read_sql函数可以通过 SQL 语句从数据库中读取数据创建DataFrame对象,该函数的第二个参数代表了需要连接的数据库。对于 MySQL 数据库,我们可以通过pymysql或mysqlclient来创建数据库连接(需要提前安装好三方库),得到一个Connection 对象,而这个对象就是read_sql函数需要的第二个参数,代码如下所示。
代码:
import pymysql
# 创建一个MySQL数据库的连接对象
conn = pymysql.connect(
host='101.42.16.8', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8mb4'
)
# 通过SQL从数据库二维表读取数据创建DataFrame
df5 = pd.read_sql('select * from tb_emp', conn, index_col='eno')
df5
提示:执行上面的代码需要先安装
pymysql库,如果尚未安装,可以先在单元格中先执行魔法指令%pip install pymysql,然后再运行上面的代码。上面的代码连接的是我部署在腾讯云上的 MySQL 数据库,公网 IP 地址:101.42.16.8,用户名:guest,密码:Guest.618,数据库:hrs,字符集:utf8mb4,大家可以使用这个数据库,但是不要进行恶意的访问。hrs数据库一共有三张表,分别是:tb_dept(部门表)、tb_emp(员工表)、tb_emp2(员工表2)。
输出:
ename job mgr sal comm dno
eno
1359 胡一刀 销售员 3344.0 1800 200.0 30
2056 乔峰 分析师 7800.0 5000 1500.0 20
3088 李莫愁 设计师 2056.0 3500 800.0 20
3211 张无忌 程序员 2056.0 3200 NaN 20
3233 丘处机 程序员 2056.0 3400 NaN 20
3244 欧阳锋 程序员 3088.0 3200 NaN 20
3251 张翠山 程序员 2056.0 4000 NaN 20
3344 黄蓉 销售主管 7800.0 3000 800.0 30
3577 杨过 会计 5566.0 2200 NaN 10
3588 朱九真 会计 5566.0 2500 NaN 10
4466 苗人凤 销售员 3344.0 2500 NaN 30
5234 郭靖 出纳 5566.0 2000 NaN 10
5566 宋远桥 会计师 7800.0 4000 1000.0 10
7800 张三丰 总裁 NaN 9000 1200.0 20
执行上面的代码会出现一个警告,因为 pandas 库希望我们使用SQLAlchemy三方库接入数据库,具体内容是:“UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.”。如果不想看到这个警告,我们可以试一试下面的解决方案。
首先,安装三方库SQLAlchemy,在 Jupyter 中可以使用%pip魔法指令。
%pip install sqlalchemy
通过SQLAlchemy的create_engine函数创建Engine对象作为read_sql函数的第二个参数,此时read_sql函数的第一个参数可以是 SQL 语句,也可以是二维表的表名。
from sqlalchemy import create_engine
# 通过指定的URL(统一资源定位符)访问数据库
engine = create_engine('mysql+pymysql://guest:Guest.618@101.42.16.8:3306/hrs')
# 直接通过表名加载整张表的数据
df5 = pd.read_sql('tb_emp', engine, index_col='eno')
df5
说明:如果通过表名加载二维表数据,也可以将上面的函数换成
read_sql_table。
我们再来加载部门表的数据创建DataFrame对象。
df6 = pd.read_sql('select dno, dname, dloc from tb_dept', engine, index_col='dno')
df6
说明:如果通过 SQL 查询获取数据,也可以将上面的函数换成
read_sql_query。
输出:
dname dloc
dno
10 会计部 北京
20 研发部 成都
30 销售部 重庆
40 运维部 深圳
在完成数据加载后,如果希望释放数据库连接,可以使用下面的代码。
engine.connect().close()
基本属性和方法
在开始讲解DataFrame的属性和方法前,我们先从之前提到的hrs数据库中读取三张表的数据,创建出三个DataFrame对象,完整的代码如下所示。
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://guest:Guest.618@101.42.16.8:3306/hrs')
dept_df = pd.read_sql_table('tb_dept', engine, index_col='dno')
emp_df = pd.read_sql_table('tb_emp', engine, index_col='eno')
emp2_df = pd.read_sql_table('tb_emp2', engine, index_col='eno')得到的三个DataFrame对象如下所示。
部门表(dept_df),其中dno是部门的编号,dname和dloc分别是部门的名称和所在地。
dname dloc
dno
10 会计部 北京
20 研发部 成都
30 销售部 重庆
40 运维部 深圳
员工表(emp_df),其中eno是员工编号,ename、job、mgr、sal、comm和dno分别代表员工的姓名、职位、主管编号、月薪、补贴和部门编号。
ename job mgr sal comm dno
eno
1359 胡一刀 销售员 3344.0 1800 200.0 30
2056 乔峰 分析师 7800.0 5000 1500.0 20
3088 李莫愁 设计师 2056.0 3500 800.0 20
3211 张无忌 程序员 2056.0 3200 NaN 20
3233 丘处机 程序员 2056.0 3400 NaN 20
3244 欧阳锋 程序员 3088.0 3200 NaN 20
3251 张翠山 程序员 2056.0 4000 NaN 20
3344 黄蓉 销售主管 7800.0 3000 800.0 30
3577 杨过 会计 5566.0 2200 NaN 10
3588 朱九真 会计 5566.0 2500 NaN 10
4466 苗人凤 销售员 3344.0 2500 NaN 30
5234 郭靖 出纳 5566.0 2000 NaN 10
5566 宋远桥 会计师 7800.0 4000 1000.0 10
7800 张三丰 总裁 NaN 9000 1200.0 20
说明:在数据库中
mgr和comm两个列的数据类型是int,但是因为有缺失值(空值),读取到DataFrame之后,列的数据类型变成了float,因为我们通常会用float类型的NaN来表示空值。
员工表(emp2_df),跟上面的员工表结构相同,但是保存了不同的员工数据。
ename job mgr sal comm dno
eno
9500 张三丰 总裁 NaN 50000 8000 20
9600 王大锤 程序员 9800.0 8000 600 20
9700 张三丰 总裁 NaN 60000 6000 20
9800 骆昊 架构师 7800.0 30000 5000 20
9900 陈小刀 分析师 9800.0 10000 1200 20
DataFrame对象的属性如下表所示。
| 属性名 | 说明 |
|---|---|
at / iat | 通过标签获取DataFrame中的单个值。 |
columns | DataFrame对象列的索引 |
dtypes | DataFrame对象每一列的数据类型 |
empty | DataFrame对象是否为空 |
loc / iloc | 通过标签获取DataFrame中的一组值。 |
ndim | DataFrame对象的维度 |
shape | DataFrame对象的形状(行数和列数) |
size | DataFrame对象中元素的个数 |
values | DataFrame对象的数据对应的二维数组 |
关于DataFrame的方法,首先需要了解的是info()方法,它可以帮助我们了解DataFrame的相关信息,如下所示。
代码:
emp_df.info()
输出:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 14 entries, 1359 to 7800
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ename 14 non-null object
1 job 14 non-null object
2 mgr 13 non-null float64
3 sal 14 non-null int64
4 comm 6 non-null float64
5 dno 14 non-null int64
dtypes: float64(2), int64(2), object(2)
memory usage: 1.3+ KB
如果需要查看DataFrame的头部或尾部的数据,可以使用head()或tail()方法,这两个方法的默认参数是5,表示获取DataFrame最前面5行或最后面5行的数据,如下所示。
emp_df.head()
输出:
ename job mgr sal comm dno
eno
1359 胡一刀 销售员 3344 1800 200 30
2056 乔峰 分析师 7800 5000 1500 20
3088 李莫愁 设计师 2056 3500 800 20
3211 张无忌 程序员 2056 3200 NaN 20
3233 丘处机 程序员 2056 3400 NaN 20
操作数据
索引和切片
如果要获取DataFrame的某一列,例如取出上面emp_df的ename列,可以使用下面的两种方式。
emp_df.ename
或者
emp_df['ename']
执行上面的代码可以发现,我们获得的是一个Series对象。事实上,DataFrame对象就是将多个Series对象组合到一起的结果。
如果要获取DataFrame的某一行,可以使用整数索引或我们设置的索引,例如取出员工编号为2056的员工数据,代码如下所示。
emp_df.iloc[1]
或者
emp_df.loc[2056]
通过执行上面的代码我们发现,单独取DataFrame 的某一行或某一列得到的都是Series对象。我们当然也可以通过花式索引来获取多个行或多个列的数据,花式索引的结果仍然是一个DataFrame对象。
获取多个列:
emp_df[['ename', 'job']]
获取多个行:
emp_df.loc[[2056, 7800, 3344]]
如果要获取或修改DataFrame 对象某个单元格的数据,需要同时指定行和列的索引,例如要获取员工编号为2056的员工的职位信息,代码如下所示。
emp_df['job'][2056]
或者
emp_df.loc[2056]['job']
或者
emp_df.loc[2056, 'job']
我们推荐大家使用第三种做法,因为它只做了一次索引运算。如果要将该员工的职位修改为“架构师”,可以使用下面的代码。
emp_df.loc[2056, 'job'] = '架构师'
当然,我们也可以通过切片操作来获取多行多列,相信大家一定已经想到了这一点。
emp_df.loc[2056:3344]
输出:
ename job mgr sal comm dno
eno
2056 乔峰 分析师 7800.0 5000 1500.0 20
3088 李莫愁 设计师 2056.0 3500 800.0 20
3211 张无忌 程序员 2056.0 3200 NaN 20
3233 丘处机 程序员 2056.0 3400 NaN 20
3244 欧阳锋 程序员 3088.0 3200 NaN 20
3251 张翠山 程序员 2056.0 4000 NaN 20
3344 黄蓉 销售主管 7800.0 3000 800.0 30
数据筛选
上面我们提到了花式索引,相信大家已经联想到了布尔索引。跟ndarray和Series一样,我们可以通过布尔索引对DataFrame对象进行数据筛选,例如我们要从emp_df中筛选出月薪超过3500的员工,代码如下所示。
emp_df[emp_df.sal > 3500]
输出:
ename job mgr sal comm dno
eno
2056 乔峰 分析师 7800.0 5000 1500.0 20
3251 张翠山 程序员 2056.0 4000 NaN 20
5566 宋远桥 会计师 7800.0 4000 1000.0 10
7800 张三丰 总裁 NaN 9000 1200.0 20
当然,我们也可以组合多个条件来进行数据筛选,例如从emp_df中筛选出月薪超过3500且部门编号为20的员工,代码如下所示。
emp_df[(emp_df.sal > 3500) & (emp_df.dno == 20)]
输出:
ename job mgr sal comm dno
eno
2056 乔峰 分析师 7800.0 5000 1500.0 20
3251 张翠山 程序员 2056.0 4000 NaN 20
7800 张三丰 总裁 NaN 9000 1200.0 20
除了使用布尔索引,DataFrame对象的query方法也可以实现数据筛选,query方法的参数是一个字符串,它代表了筛选数据使用的表达式,而且更符合 Python 程序员的使用习惯。下面我们使用query方法将上面的效果重新实现一遍,代码如下所示。
emp_df.query('sal > 3500 and dno == 20')在完成数据加载之后,我们可能需要对事实表和维度表进行连接,这是对数据进行多维度拆解的基础;我们可能从不同的数据源加载了结构相同的数据,我们需要将这些数据拼接起来;我们把这些操作统称为数据重塑。当然,由于企业的信息化水平以及数据中台建设水平的差异,我们拿到的数据未必是质量很好的,可能还需要对数据中的缺失值、重复值、异常值进行适当的处理。即便我们获取的数据在质量上是没有问题的,但也可能需要对数据进行一系列的预处理,才能满足我们做数据分析的需求。接下来,我们就为大家讲解和梳理这方面的知识。
数据重塑
有的时候,我们做数据分析需要的原始数据可能并不是来自一个地方,就像上一章的例子中,我们从关系型数据库中读取了三张表,得到了三个DataFrame对象,但实际工作可能需要我们把他们的数据整合到一起。例如:emp_df和emp2_df其实都是员工的数据,而且数据结构完全一致,我们可以使用pandas提供的concat函数实现两个或多个DataFrame的数据拼接,代码如下所示。
all_emp_df = pd.concat([emp_df, emp2_df])
输出:
ename job mgr sal comm dno
eno
1359 胡一刀 销售员 3344.0 1800 200.0 30
2056 乔峰 分析师 7800.0 5000 1500.0 20
3088 李莫愁 设计师 2056.0 3500 800.0 20
3211 张无忌 程序员 2056.0 3200 NaN 20
3233 丘处机 程序员 2056.0 3400 NaN 20
3244 欧阳锋 程序员 3088.0 3200 NaN 20
3251 张翠山 程序员 2056.0 4000 NaN 20
3344 黄蓉 销售主管 7800.0 3000 800.0 30
3577 杨过 会计 5566.0 2200 NaN 10
3588 朱九真 会计 5566.0 2500 NaN 10
4466 苗人凤 销售员 3344.0 2500 NaN 30
5234 郭靖 出纳 5566.0 2000 NaN 10
5566 宋远桥 会计师 7800.0 4000 1000.0 10
7800 张三丰 总裁 NaN 9000 1200.0 20
9500 张三丰 总裁 NaN 50000 8000.0 20
9600 王大锤 程序员 9800.0 8000 600.0 20
9700 张三丰 总裁 NaN 60000 6000.0 20
9800 骆昊 架构师 7800.0 30000 5000.0 20
9900 陈小刀 分析师 9800.0 10000 1200.0 20
上面的代码将两个代表员工数据的DataFrame拼接到了一起,接下来我们使用merge函数将员工表和部门表的数据合并到一张表中,代码如下所示。
先使用reset_index方法重新设置all_emp_df的索引,这样eno 不再是索引而是一个普通列,reset_index方法的inplace参数设置为True表示,重置索引的操作直接在all_emp_df上执行,而不是返回修改后的新对象。
all_emp_df.reset_index(inplace=True)
通过merge函数合并数据,当然,也可以调用DataFrame对象的merge方法来达到同样的效果。
pd.merge(all_emp_df, dept_df, how='inner', on='dno')
输出:
eno ename job mgr sal comm dno dname dloc
0 1359 胡一刀 销售员 3344.0 1800 200.0 30 销售部 重庆
1 3344 黄蓉 销售主管 7800.0 3000 800.0 30 销售部 重庆
2 4466 苗人凤 销售员 3344.0 2500 NaN 30 销售部 重庆
3 2056 乔峰 分析师 7800.0 5000 1500.0 20 研发部 成都
4 3088 李莫愁 设计师 2056.0 3500 800.0 20 研发部 成都
5 3211 张无忌 程序员 2056.0 3200 NaN 20 研发部 成都
6 3233 丘处机 程序员 2056.0 3400 NaN 20 研发部 成都
7 3244 欧阳锋 程序员 3088.0 3200 NaN 20 研发部 成都
8 3251 张翠山 程序员 2056.0 4000 NaN 20 研发部 成都
9 7800 张三丰 总裁 NaN 9000 1200.0 20 研发部 成都
10 9500 张三丰 总裁 NaN 50000 8000.0 20 研发部 成都
11 9600 王大锤 程序员 9800.0 8000 600.0 20 研发部 成都
12 9700 张三丰 总裁 NaN 60000 6000.0 20 研发部 成都
13 9800 骆昊 架构师 7800.0 30000 5000.0 20 研发部 成都
14 9900 陈小刀 分析师 9800.0 10000 1200.0 20 研发部 成都
15 3577 杨过 会计 5566.0 2200 NaN 10 会计部 北京
16 3588 朱九真 会计 5566.0 2500 NaN 10 会计部 北京
17 5234 郭靖 出纳 5566.0 2000 NaN 10 会计部 北京
18 5566 宋远桥 会计师 7800.0 4000 1000.0 10 会计部 北京
merge函数的一个参数代表合并的左表、第二个参数代表合并的右表,有SQL编程经验的同学对这两个词是不是感觉到非常亲切。正如大家猜想的那样,DataFrame对象的合并跟数据库中的表连接非常类似,所以上面代码中的how代表了合并两张表的方式,有left、right、inner、outer四个选项;而on则代表了基于哪个列实现表的合并,相当于 SQL 表连接中的连表条件,如果左右两表对应的列列名不同,可以用left_on和right_on参数取代on参数分别进行指定。
如果对上面的代码稍作修改,将how参数修改为'right',大家可以思考一下代码执行的结果。
pd.merge(all_emp_df, dept_df, how='right', on='dno')
运行结果比之前的输出多出了如下所示的一行,这是因为how='right'代表右外连接,也就意味着右表dept_df中的数据会被完整的查出来,但是在all_emp_df中又没有编号为40 部门的员工,所以对应的位置都被填入了空值。
19 NaN NaN NaN NaN NaN NaN 40 运维部 深圳
数据清洗
通常,我们从 Excel、CSV 或数据库中获取到的数据并不是非常完美的,里面可能因为系统或人为的原因混入了重复值或异常值,也可能在某些字段上存在缺失值;再者,DataFrame中的数据也可能存在格式不统一、量纲不统一等各种问题。因此,在开始数据分析之前,对数据进行清洗就显得特别重要。
缺失值
可以使用DataFrame对象的isnull或isna方法来找出数据表中的缺失值,如下所示。
emp_df.isnull()
或者
emp_df.isna()
输出:
ename job mgr sal comm dno eno 1359 False False False False False False 2056 False False False False False False 3088 False False False False False False 3211 False False False False True False 3233 False False False False True False 3244 False False False False True False 3251 False False False False True False 3344 False False False False False False 3577 False False False False True False 3588 False False False False True False 4466 False False False False True False 5234 False False False False True False 5566 False False False False False False 7800 False False True False False False
相对应的,notnull和notna方法可以将非空的值标记为True。如果想删除这些缺失值,可以使用DataFrame对象的dropna方法,该方法的axis参数可以指定沿着0轴还是1轴删除,也就是说当遇到空值时,是删除整行还是删除整列,默认是沿0轴进行删除的,代码如下所示。
emp_df.dropna()
输出:
ename job mgr sal comm dno eno 1359 胡一刀 销售员 3344.0 1800 200.0 30 2056 乔峰 架构师 7800.0 5000 1500.0 20 3088 李莫愁 设计师 2056.0 3500 800.0 20 3344 黄蓉 销售主管 7800.0 3000 800.0 30 5566 宋远桥 会计师 7800.0 4000 1000.0 10
如果要沿着1轴进行删除,可以使用下面的代码。
emp_df.dropna(axis=1)
输出:
ename job sal dno eno 1359 胡一刀 销售员 1800 30 2056 乔峰 架构师 5000 20 3088 李莫愁 设计师 3500 20 3211 张无忌 程序员 3200 20 3233 丘处机 程序员 3400 20 3244 欧阳锋 程序员 3200 20 3251 张翠山 程序员 4000 20 3344 黄蓉 销售主管 3000 30 3577 杨过 会计 2200 10 3588 朱九真 会计 2500 10 4466 苗人凤 销售员 2500 30 5234 郭靖 出纳 2000 10 5566 宋远桥 会计师 4000 10 7800 张三丰 总裁 9000 20
注意:
DataFrame对象的很多方法都有一个名为inplace的参数,该参数的默认值为False,表示我们的操作不会修改原来的DataFrame对象,而是将处理后的结果通过一个新的DataFrame对象返回。如果将该参数的值设置为True,那么我们的操作就会在原来的DataFrame上面直接修改,方法的返回值为None。简单的说,上面的操作并没有修改emp_df,而是返回了一个新的DataFrame对象。
在某些特定的场景下,我们可以对空值进行填充,对应的方法是fillna,填充空值时可以使用指定的值(通过value参数进行指定),也可以用表格中前一个单元格(通过设置参数method=ffill)或后一个单元格(通过设置参数method=bfill)的值进行填充,当代码如下所示。
emp_df.fillna(value=0)
注意:填充的值如何选择也是一个值得探讨的话题,实际工作中,可能会使用某种统计量(如:均值、众数等)进行填充,或者使用某种插值法(如:随机插值法、拉格朗日插值法等)进行填充,甚至有可能通过回归模型、贝叶斯模型等对缺失数据进行填充。
输出:
ename job mgr sal comm dno eno 1359 胡一刀 销售员 3344.0 1800 200.0 30 2056 乔峰 分析师 7800.0 5000 1500.0 20 3088 李莫愁 设计师 2056.0 3500 800.0 20 3211 张无忌 程序员 2056.0 3200 0.0 20 3233 丘处机 程序员 2056.0 3400 0.0 20 3244 欧阳锋 程序员 3088.0 3200 0.0 20 3251 张翠山 程序员 2056.0 4000 0.0 20 3344 黄蓉 销售主管 7800.0 3000 800.0 30 3577 杨过 会计 5566.0 2200 0.0 10 3588 朱九真 会计 5566.0 2500 0.0 10 4466 苗人凤 销售员 3344.0 2500 0.0 30 5234 郭靖 出纳 5566.0 2000 0.0 10 5566 宋远桥 会计师 7800.0 4000 1000.0 10 7800 张三丰 总裁 0.0 9000 1200.0 20
重复值
接下来,我们先给之前的部门表添加两行数据,让部门表中名为“研发部”和“销售部”的部门各有两个。
dept_df.loc[50] = {'dname': '研发部', 'dloc': '上海'}
dept_df.loc[60] = {'dname': '销售部', 'dloc': '长沙'}
dept_df输出:
dname dloc dno 10 会计部 北京 20 研发部 成都 30 销售部 重庆 40 运维部 天津 50 研发部 上海 60 销售部 长沙
现在,我们的数据表中有重复数据了,我们可以通过DataFrame对象的duplicated方法判断是否存在重复值,该方法在不指定参数时默认判断行索引是否重复,我们也可以指定根据部门名称dname判断部门是否重复,代码如下所示。
dept_df.duplicated('dname')输出:
dno 10 False 20 False 30 False 40 False 50 True 60 True dtype: bool
从上面的输出可以看到,50和60两个部门从部门名称上来看是重复的,如果要删除重复值,可以使用drop_duplicates方法,该方法的keep参数可以控制在遇到重复值时,保留第一项还是保留最后一项,或者多个重复项一个都不用保留,全部删除掉。
dept_df.drop_duplicates('dname')输出:
dname dloc dno 10 会计部 北京 20 研发部 成都 30 销售部 重庆 40 运维部 天津
将keep参数的值修改为last。
dept_df.drop_duplicates('dname', keep='last')输出:
dname dloc dno 10 会计部 北京 40 运维部 天津 50 研发部 上海 60 销售部 长沙
使用同样的方式,我们也可以清除all_emp_df中的重复数据,例如我们认定“ename”和“job”两个字段完全相同的就是重复数据,我们可以用下面的代码去除重复数据。
all_emp_df.drop_duplicates(['ename', 'job'], inplace=True)
说明:上面的
drop_duplicates方法添加了参数inplace=True,该方法不会返回新的DataFrame对象,而是在原来的DataFrame对象上直接删除,大家可以查看all_emp_df看看是不是已经移除了重复的员工数据。
异常值
异常值在统计学上的全称是疑似异常值,也称作离群点(outlier),异常值的分析也称作离群点分析。异常值是指样本中出现的“极端值”,数据值看起来异常大或异常小,其分布明显偏离其余的观测值。实际工作中,有些异常值可能是由系统或人为原因造成的,但有些异常值却不是,它们能够重复且稳定的出现,属于正常的极端值,例如很多游戏产品中头部玩家的数据往往都是离群的极端值。所以,我们既不能忽视异常值的存在,也不能简单地把异常值从数据分析中剔除。重视异常值的出现,分析其产生的原因,常常成为发现问题进而改进决策的契机。
异常值的检测有Z-score 方法、IQR 方法、DBScan 聚类、孤立森林等,这里我们对前两种方法做一个简单的介绍。
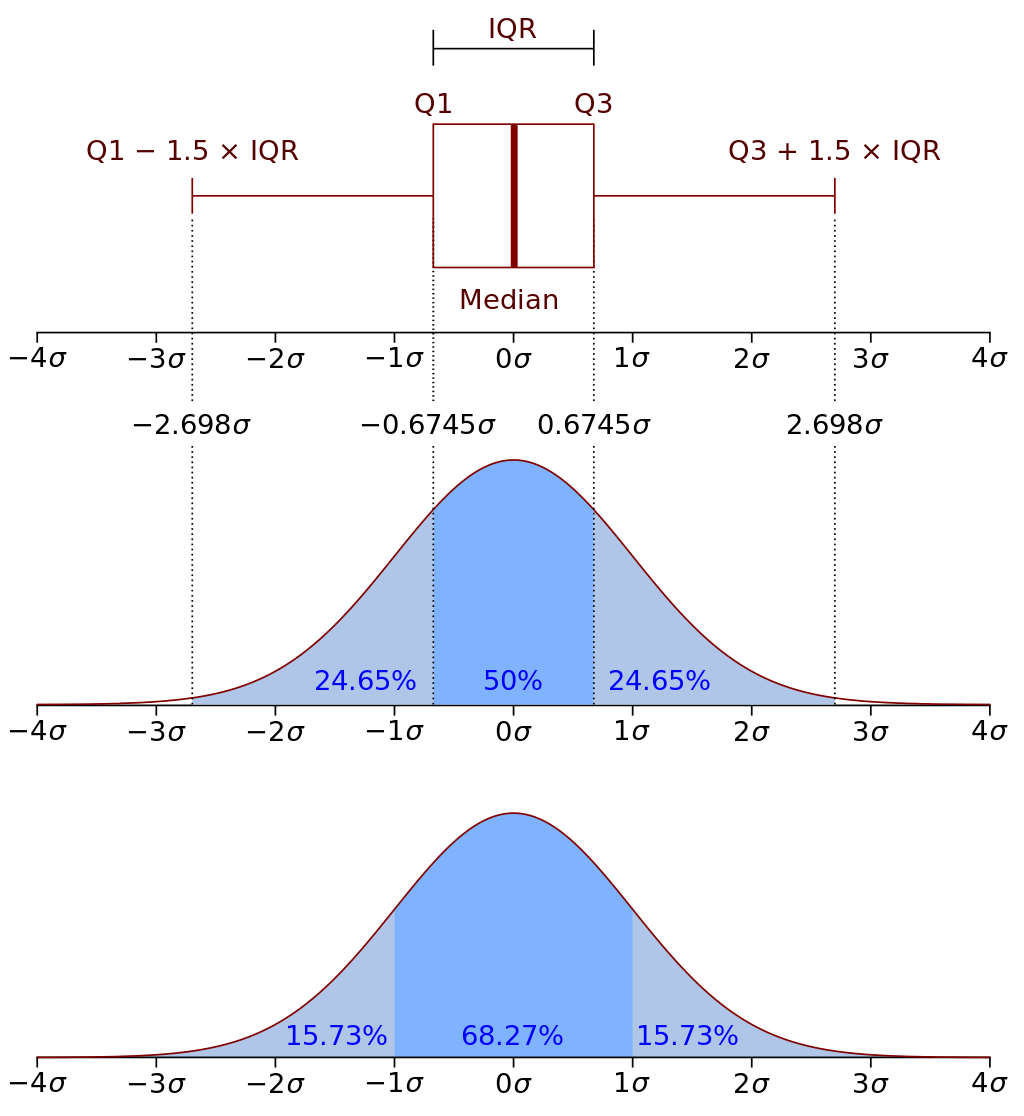
如果数据服从正态分布,依据3σ法则,异常值被定义与平均值的偏差超过三倍标准差的值。在正态分布下,距离平均值3σ之外的值出现的概率为 $\small{P(\lvert x - \mu \rvert \gt 3 \sigma) < 0.003}$ ,属于小概率事件。如果数据不服从正态分布,那么可以用远离均值的多少倍的标准差来描述,这里的倍数就是Z-score。Z-score以标准差为单位去度量某一原始分数偏离平均值的距离,公式如下所示。


Z-score需要根据经验和实际情况来决定,通常把远离标准差 3 倍距离以上的数据点视为离群点,下面的代给出了如何通过Z-score方法检测异常值。
def detect_outliers_zscore(data, threshold=3): avg_value = np.mean(data) std_value = np.std(data) z_score = np.abs((data - avg_value) / std_value) return data[z_score > threshold]
IQR 方法中的 IQR(Inter-Quartile Range)代表四分位距离,即上四分位数(Q3)和下四分位数(Q1)的差值。通常情况下,可以认为小于 $\small{Q1 - 1.5 \times IQR}$ 或大于 $\small{Q3 + 1.5 \times IQR}$ 的就是异常值,而这种检测异常值的方法也是箱线图(后面会讲到)默认使用的方法。下面的代码给出了如何通过 IQR 方法检测异常值。
def detect_outliers_iqr(data, whis=1.5): q1, q3 = np.quantile(data, [0.25, 0.75]) iqr = q3 - q1 lower, upper = q1 - whis * iqr, q3 + whis * iqr return data[(data < lower) | (data > upper)]
如果要删除异常值,可以使用DataFrame对象的drop方法,该方法可以根据行索引或列索引删除指定的行或列。例如我们认为月薪低于2000或高于8000的是员工表中的异常值,可以用下面的代码删除对应的记录。
emp_df.drop(emp_df[(emp_df.sal > 8000) | (emp_df.sal < 2000)].index)
如果要替换掉异常值,可以通过给单元格赋值的方式来实现,也可以使用replace方法将指定的值替换掉。例如我们要将月薪为1800和9000的替换为月薪的平均值,补贴为800的替换为1000,代码如下所示。
avg_sal = np.mean(emp_df.sal).astype(int)
emp_df.replace({'sal': [1800, 9000], 'comm': 800}, {'sal': avg_sal, 'comm': 1000})预处理
对数据进行预处理也是一个很大的话题,它包含了对数据的拆解、变换、归约、离散化等操作。我们先来看看数据的拆解。如果数据表中的数据是一个时间日期,我们通常都需要从年、季度、月、日、星期、小时、分钟等维度对其进行拆解,如果时间日期是用字符串表示的,可以先通过pandas的to_datetime函数将其处理成时间日期。
在下面的例子中,我们先读取 Excel 文件,获取到一组销售数据,其中第一列就是销售日期,我们将其拆解为“月份”、“季度”和“星期”,代码如下所示。
sales_df = pd.read_excel( 'data/2020年销售数据.xlsx', usecols=['销售日期', '销售区域', '销售渠道', '品牌', '销售额'] ) sales_df.info()
说明:上面代码中使用了相对路径来获取 Excel 文件,也就是说 Excel 文件在当前工作路径下名为
data的文件夹中。如果需要上面例子中的 Excel 文件,可以通过下面的百度云盘地址进行获取。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g,提取码:e7b4。
输出:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1945 entries, 0 to 1944 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 销售日期 1945 non-null datetime64[ns] 1 销售区域 1945 non-null object 2 销售渠道 1945 non-null object 3 品牌 1945 non-null object 4 销售额 1945 non-null int64 dtypes: datetime64[ns](1), int64(1), object(3) memory usage: 76.1+ KB
sales_df['月份'] = sales_df['销售日期'].dt.month sales_df['季度'] = sales_df['销售日期'].dt.quarter sales_df['星期'] = sales_df['销售日期'].dt.weekday sales_df
输出:
销售日期 销售区域 销售渠道 品牌 销售额 月份 季度 星期 0 2020-01-01 上海 拼多多 八匹马 8217 1 1 2 1 2020-01-01 上海 抖音 八匹马 6351 1 1 2 2 2020-01-01 上海 天猫 八匹马 14365 1 1 2 3 2020-01-01 上海 天猫 八匹马 2366 1 1 2 4 2020-01-01 上海 天猫 皮皮虾 15189 1 1 2 ... ... ... ... ... ... ... ... ... 1940 2020-12-30 北京 京东 花花姑娘 6994 12 4 2 1941 2020-12-30 福建 实体 八匹马 7663 12 4 2 1942 2020-12-31 福建 实体 花花姑娘 14795 12 4 3 1943 2020-12-31 福建 抖音 八匹马 3481 12 4 3 1944 2020-12-31 福建 天猫 八匹马 2673 12 4 3
在上面的代码中,通过日期时间类型的Series对象的dt 属性,获得一个访问日期时间的对象,通过该对象的year、month、quarter、hour等属性,就可以获取到年、月、季度、小时等时间信息,获取到的仍然是一个Series对象,它包含了一组时间信息,所以我们通常也将这个dt属性称为“日期时间向量”。
我们再来说一说字符串类型的数据的处理,我们先从指定的 Excel 文件中读取某招聘网站的招聘数据。
jobs_df = pd.read_csv( 'data/某招聘网站招聘数据.csv', usecols=['city', 'companyFullName', 'positionName', 'salary'] ) jobs_df.info()
说明:上面代码中使用了相对路径来获取 CSV 文件,也就是说 CSV 文件在当前工作路径下名为
data的文件夹中。如果需要上面例子中的 CSV 文件,可以通过下面的百度云盘地址进行获取。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g,提取码:e7b4。
输出:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 3140 entries, 0 to 3139 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 city 3140 non-null object 1 companyFullName 3140 non-null object 2 positionName 3140 non-null object 3 salary 3140 non-null object dtypes: object(4) memory usage: 98.2+ KB
查看前5条数据。
jobs_df.head()
输出:
city companyFullName positionName salary 0 北京 达疆网络科技(上海)有限公司 数据分析岗 15k-30k 1 北京 北京音娱时光科技有限公司 数据分析 10k-18k 2 北京 北京千喜鹤餐饮管理有限公司 数据分析 20k-30k 3 北京 吉林省海生电子商务有限公司 数据分析 33k-50k 4 北京 韦博网讯科技(北京)有限公司 数据分析 10k-15k
上面的数据表一共有3140条数据,但并非所有的职位都是“数据分析”的岗位,如果要筛选出数据分析的岗位,可以通过检查positionName字段是否包含“数据分析”这个关键词,这里需要模糊匹配,应该如何实现呢?我们可以先获取positionName列,因为这个Series对象的dtype是字符串,所以可以通过str属性获取对应的字符串向量,然后就可以利用我们熟悉的字符串的方法来对其进行操作,代码如下所示。
jobs_df = jobs_df[jobs_df.positionName.str.contains('数据分析')]
jobs_df.shape输出:
(1515, 4)
可以看出,筛选后的数据还有1515条。接下来,我们还需要对salary字段进行处理,如果我们希望统计所有岗位的平均工资或每个城市的平均工资,首先需要将用范围表示的工资处理成其中间值,代码如下所示。
jobs_df.salary.str.extract(r'(\d+)[kK]?-(\d+)[kK]?')
说明:上面的代码通过正则表达式捕获组从字符串中抽取出两组数字,分别对应工资的下限和上限,对正则表达式不熟悉的读者,可以阅读我的知乎专栏“从零开始学Python”中的一文。
输出:
0 1 0 15 30 1 10 18 2 20 30 3 33 50 4 10 15 ... ... ... 3065 8 10 3069 6 10 3070 2 4 3071 6 12 3088 8 12
需要提醒大家的是,抽取出来的两列数据都是字符串类型的值,我们需要将其转换成int类型,才能计算平均值,对应的方法是DataFrame对象的applymap方法,该方法的参数是一个函数,而该函数会作用于DataFrame中的每个元素。完成这一步之后,我们就可以使用apply方法将上面的DataFrame处理成中间值,apply方法的参数也是一个函数,可以通过指定axis参数使其作用于DataFrame 对象的行或列,代码如下所示。
temp_df = jobs_df.salary.str.extract(r'(\d+)[kK]?-(\d+)[kK]?').applymap(int) temp_df.apply(np.mean, axis=1)
输出:
0 22.5 1 14.0 2 25.0 3 41.5 4 12.5 ... 3065 9.0 3069 8.0 3070 3.0 3071 9.0 3088 10.0 Length: 1515, dtype: float64
接下来,我们可以用上面的结果替换掉原来的salary列或者增加一个新的列来表示职位对应的工资,完整的代码如下所示。
temp_df = jobs_df.salary.str.extract(r'(\d+)[kK]?-(\d+)[kK]?').applymap(int) jobs_df['salary'] = temp_df.apply(np.mean, axis=1) jobs_df.head()
输出:
city companyFullName positionName salary 0 北京 达疆网络科技(上海)有限公司 数据分析岗 22.5 1 北京 北京音娱时光科技有限公司 数据分析 14.0 2 北京 北京千喜鹤餐饮管理有限公司 数据分析 25.0 3 北京 吉林省海生电子商务有限公司 数据分析 41.5 4 北京 韦博网讯科技(北京)有限公司 数据分析 12.5
applymap和apply两个方法在数据预处理的时候经常用到,Series对象也有apply方法,也是用于数据的预处理,但是DataFrame对象还有一个名为transform 的方法,也是通过传入的函数对数据进行变换,类似Series对象的map方法。需要强调的是,apply方法具有归约效果的,简单的说就是能将较多的数据处理成较少的数据或一条数据;而transform方法没有归约效果,只能对数据进行变换,原来有多少条数据,处理后还是有多少条数据。
如果要对数据进行深度的分析和挖掘,字符串、日期时间这样的非数值类型都需要处理成数值,因为非数值类型没有办法计算相关性,也没有办法进行 $\small{\chi^{2}}$ 检验等操作。对于字符串类型,通常可以其分为以下三类,再进行对应的处理。
有序变量(Ordinal Variable):字符串表示的数据有顺序关系,那么可以对字符串进行序号化处理。
分类变量(Categorical Variable)/ 名义变量(Nominal Variable):字符串表示的数据没有大小关系和等级之分,那么就可以使用独热编码的方式处理成哑变量(虚拟变量)矩阵。
定距变量(Scale Variable):字符串本质上对应到一个有大小高低之分的数据,而且可以进行加减运算,那么只需要将字符串处理成对应的数值即可。
对于第1类和第3类,我们可以用上面提到的apply或transform方法来处理,也可以利用scikit-learn中的OrdinalEncoder处理第1类字符串,这个我们在后续的课程中会讲到。对于第2类字符串,可以使用pandas的get_dummies()函数来生成哑变量(虚拟变量)矩阵,代码如下所示。
persons_df = pd.DataFrame(
data={
'姓名': ['关羽', '张飞', '赵云', '马超', '黄忠'],
'职业': ['医生', '医生', '程序员', '画家', '教师'],
'学历': ['研究生', '大专', '研究生', '高中', '本科']
}
)
persons_df输出:
姓名 职业 学历 0 关羽 医生 研究生 1 张飞 医生 大专 2 赵云 程序员 研究生 3 马超 画家 高中 4 黄忠 教师 本科
将职业处理成哑变量矩阵。
pd.get_dummies(persons_df['职业'])
输出:
医生 教师 画家 程序员 0 1 0 0 0 1 1 0 0 0 2 0 0 0 1 3 0 0 1 0 4 0 1 0 0
将学历处理成大小不同的值。
def handle_education(x):
edu_dict = {'高中': 1, '大专': 3, '本科': 5, '研究生': 10}
return edu_dict.get(x, 0)
persons_df['学历'].apply(handle_education)输出:
0 10 1 3 2 10 3 1 4 5 Name: 学历, dtype: int64
我们再来说说数据离散化。离散化也叫分箱,如果变量的取值是连续值,那么它的取值有无数种可能,在进行数据分组的时候就会非常的不方便,这个时候将连续变量离散化就显得非常重要。之所以把离散化叫做分箱,是因为我们可以预先设置一些箱子,每个箱子代表了数据取值的范围,这样就可以将连续的值分配到不同的箱子中,从而实现离散化。下面的例子读取了2018年北京积分落户数据,我们可以根据落户积分对数据进行分组,具体的做法如下所示。
luohu_df = pd.read_csv('data/2018年北京积分落户数据.csv', index_col='id')
luohu_df.score.describe()输出:
count 6019.000000 mean 95.654552 std 4.354445 min 90.750000 25% 92.330000 50% 94.460000 75% 97.750000 max 122.590000 Name: score, dtype: float64
可以看出,落户积分的最大值是122.59,最小值是90.75,那么我们可以构造一个从90分到125分,每5分一组的7个箱子,pandas的cut函数可以帮助我们首先数据分箱,代码如下所示。
bins = np.arange(90, 126, 5) pd.cut(luohu_df.score, bins, right=False)
说明:
cut函数的right参数默认值为True,表示箱子左开右闭;修改为False可以让箱子的右边界为开区间,左边界为闭区间,大家看看下面的输出就明白了。
输出:
id 1 [120, 125) 2 [120, 125) 3 [115, 120) 4 [115, 120) 5 [115, 120) ... 6015 [90, 95) 6016 [90, 95) 6017 [90, 95) 6018 [90, 95) 6019 [90, 95) Name: score, Length: 6019, dtype: category Categories (7, interval[int64, left]): [[90, 95) < [95, 100) < [100, 105) < [105, 110) < [110, 115) < [115, 120) < [120, 125)]
我们可以根据分箱的结果对数据进行分组,然后使用聚合函数对每个组进行统计,这是数据分析中经常用到的操作,下一个章节会为大家介绍。除此之外,pandas还提供了一个名为qcut的函数,可以指定分位数对数据进行分箱,有兴趣的读者可以自行研究。
数据透视
经过前面的学习,我们已经将数据准备就绪而且变成了我们想要的样子,接下来就是最为重要的数据透视阶段了。当我们拿到一大堆数据的时候,如何从数据中迅速的解读出有价值的信息,把繁杂的数据变成容易解读的统计图表并再此基础上产生业务洞察,这就是数据分析要解决的核心问题。
获取描述性统计信息
首先,我们可以获取数据的描述性统计信息,通过描述性统计信息,我们可以了解数据的集中趋势和离散趋势。
例如,我们有如下所示的学生成绩表。
scores = np.random.randint(50, 101, (5, 3))
names = ('关羽', '张飞', '赵云', '马超', '黄忠')
courses = ('语文', '数学', '英语')
df = pd.DataFrame(data=scores, columns=courses, index=names)
df
输出:
语文 数学 英语
关羽 96 72 73
张飞 72 70 97
赵云 74 51 79
马超 100 54 54
黄忠 89 100 88
我们可以通过DataFrame对象的方法mean、max、min、std、var等方法分别获取每个学生或每门课程的平均分、最高分、最低分、标准差、方差等信息,也可以直接通过describe方法直接获取描述性统计信息,代码如下所示。
计算每门课程成绩的平均分。
df.mean()
输出:
语文 86.2
数学 69.4
英语 78.2
dtype: float64
计算每个学生成绩的平均分。
df.mean(axis=1)
输出:
关羽 80.333333
张飞 79.666667
赵云 68.000000
马超 69.333333
黄忠 92.333333
dtype: float64
计算每门课程成绩的方差。
df.var()
输出:
语文 161.2
数学 379.8
英语 265.7
dtype: float64
说明:通过方差可以看出,数学成绩波动最大,两极分化可能更严重。
获取每门课程的描述性统计信息。
df.describe()
输出:
语文 数学 英语
count 5.000000 5.000000 5.000000
mean 86.200000 69.400000 78.200000
std 12.696456 19.488458 16.300307
min 72.000000 51.000000 54.000000
25% 74.000000 54.000000 73.000000
50% 89.000000 70.000000 79.000000
75% 96.000000 72.000000 88.000000
max 100.000000 100.000000 97.000000
排序和取头部值
如果需要对数据进行排序,可以使用DataFrame对象的sort_values方法,该方法的by参数可以指定根据哪个列或哪些列进行排序,而ascending参数可以指定升序或是降序。例如,下面的代码展示了如何将学生表按语文成绩排降序。
df.sort_values(by='语文', ascending=False)
输出:
语文 数学 英语
马超 100 54 54
关羽 96 72 73
黄忠 89 100 88
赵云 74 51 79
张飞 72 70 97
如果DataFrame数据量很大,排序将是一个非常耗费时间的操作。有的时候我们只需要获得排前N名或后N名的数据,这个时候其实没有必要对整个数据进行排序,而是直接利用堆结构找出Top-N的数据。DataFrame的nlargest和nsmallest方法就提供对Top-N操作的支持,代码如下所示。
找出语文成绩前3名的学生信息。
df.nlargest(3, '语文')
输出:
语文 数学 英语
马超 100 54 54
关羽 96 72 73
黄忠 89 100 88
找出数学成绩最低的3名学生的信息。
df.nsmallest(3, '数学')
输出:
语文 数学 英语
赵云 74 51 79
马超 100 54 54
张飞 72 70 97
分组聚合
我们先从之前使用过的 Excel 文件中读取2020年销售数据,然后再为大家演示如何进行分组聚合操作。
df = pd.read_excel('data/2020年销售数据.xlsx')
df.head()
输出:
销售日期 销售区域 销售渠道 销售订单 品牌 售价 销售数量
0 2020-01-01 上海 拼多多 182894-455 八匹马 99 83
1 2020-01-01 上海 抖音 205635-402 八匹马 219 29
2 2020-01-01 上海 天猫 205654-021 八匹马 169 85
3 2020-01-01 上海 天猫 205654-519 八匹马 169 14
4 2020-01-01 上海 天猫 377781-010 皮皮虾 249 61
如果我们要统计每个销售区域的销售总额,可以先通过“售价”和“销售数量”计算出销售额,为DataFrame添加一个列,代码如下所示。
df['销售额'] = df['售价'] * df['销售数量']
df.head()
输出:
销售日期 销售区域 销售渠道 销售订单 品牌 售价 销售数量 销售额
0 2020-01-01 上海 拼多多 182894-455 八匹马 99 83 8217
1 2020-01-01 上海 抖音 205635-402 八匹马 219 29 6351
2 2020-01-01 上海 天猫 205654-021 八匹马 169 85 14365
3 2020-01-01 上海 天猫 205654-519 八匹马 169 14 2366
4 2020-01-01 上海 天猫 377781-010 皮皮虾 249 61 15189
然后再根据“销售区域”列对数据进行分组,这里我们使用的是DataFrame对象的groupby方法。分组之后,我们取“销售额”这个列在分组内进行求和处理,代码和结果如下所示。
df.groupby('销售区域').销售额.sum()输出:
销售区域
上海 11610489
北京 12477717
安徽 895463
广东 1617949
江苏 2304380
浙江 687862
福建 10178227
Name: 销售额, dtype: int64
如果我们要统计每个月的销售总额,我们可以将“销售日期”作为groupby`方法的参数,当然这里需要先将“销售日期”处理成月,代码和结果如下所示。
df.groupby(df['销售日期'].dt.month).销售额.sum()
输出:
销售日期
1 5409855
2 4608455
3 4164972
4 3996770
5 3239005
6 2817936
7 3501304
8 2948189
9 2632960
10 2375385
11 2385283
12 1691973
Name: 销售额, dtype: int64
接下来我们将难度升级,统计每个销售区域每个月的销售总额,这又该如何处理呢?事实上,groupby方法的第一个参数可以是一个列表,列表中可以指定多个分组的依据,大家看看下面的代码和输出结果就明白了。
df.groupby(['销售区域', df['销售日期'].dt.month]).销售额.sum()
输出:
销售区域 销售日期
上海 1 1679125
2 1689527
3 1061193
4 1082187
5 841199
6 785404
7 863906
8 734937
9 1107693
10 412108
11 825169
12 528041
北京 1 1878234
2 1807787
3 1360666
4 1205989
5 807300
6 1216432
7 1219083
8 645727
9 390077
10 671608
11 678668
12 596146
安徽 4 341308
5 554155
广东 3 388180
8 469390
9 365191
11 395188
江苏 4 537079
7 841032
10 710962
12 215307
浙江 3 248354
8 439508
福建 1 1852496
2 1111141
3 1106579
4 830207
5 1036351
6 816100
7 577283
8 658627
9 769999
10 580707
11 486258
12 352479
Name: 销售额, dtype: int64
如果希望统计出每个区域的销售总额以及每个区域单笔金额的最高和最低,我们可以在DataFrame或Series对象上使用agg方法并指定多个聚合函数,代码和结果如下所示。
df.groupby('销售区域').销售额.agg(['sum', 'max', 'min'])输出:
sum max min
销售区域
上海 11610489 116303 948
北京 12477717 133411 690
安徽 895463 68502 1683
广东 1617949 120807 990
江苏 2304380 114312 1089
浙江 687862 90909 3927
福建 10178227 87527 897
如果希望自定义聚合后的列的名字,可以使用如下所示的方法。
df.groupby('销售区域').销售额.agg(销售总额='sum', 单笔最高='max', 单笔最低='min')输出:
销售总额 单笔最高 单笔最低
销售区域
上海 11610489 116303 948
北京 12477717 133411 690
安徽 895463 68502 1683
广东 1617949 120807 990
江苏 2304380 114312 1089
浙江 687862 90909 3927
福建 10178227 87527 897
如果需要对多个列使用不同的聚合函数,例如“统计每个销售区域销售额的总和以及销售数量的最低值和最高值”,我们可以按照下面的方式来操作。
df.groupby('销售区域')[['销售额', '销售数量']].agg({
'销售额': 'sum', '销售数量': ['max', 'min']
})
输出:
销售额 销售数量
sum max min
销售区域
上海 11610489 100 10
北京 12477717 100 10
安徽 895463 98 16
广东 1617949 98 10
江苏 2304380 100 11
浙江 687862 95 20
福建 10178227 100 10
透视表和交叉表
上面的例子中,“统计每个销售区域每个月的销售总额”会产生一个看起来很长的结果,在实际工作中我们通常把那些行很多列很少的表成为“窄表”,如果我们不想得到这样的一个“窄表”,可以使用DataFrame的pivot_table方法或者是pivot_table函数来生成透视表。透视表的本质就是对数据进行分组聚合操作,根据 A 列对 B 列进行统计,如果大家有使用 Excel 的经验,相信对透视表这个概念一定不会陌生。例如,我们要“统计每个销售区域的销售总额”,那么“销售区域”就是我们的 A 列,而“销售额”就是我们的 B 列,在pivot_table函数中分别对应index和values参数,这两个参数都可以是单个列或者多个列。
pd.pivot_table(df, index='销售区域', values='销售额', aggfunc='sum')
输出:
销售额
销售区域
上海 11610489
北京 12477717
安徽 895463
广东 1617949
江苏 2304380
浙江 687862
福建 10178227
注意:上面的结果操作跟之前用
groupby的方式得到的结果有一些区别,groupby操作后,如果对单个列进行聚合,得到的结果是一个Series对象,而上面的结果是一个DataFrame对象。
如果要统计每个销售区域每个月的销售总额,也可以使用pivot_table函数,代码如下所示。
df['月份'] = df['销售日期'].dt.month
pd.pivot_table(df, index=['销售区域', '月份'], values='销售额', aggfunc='sum')
上面的操作结果是一个DataFrame,但也是一个长长的“窄表”,如果希望做成一个行比较少列比较多的“宽表”,可以将index参数中的列放到columns参数中,代码如下所示。
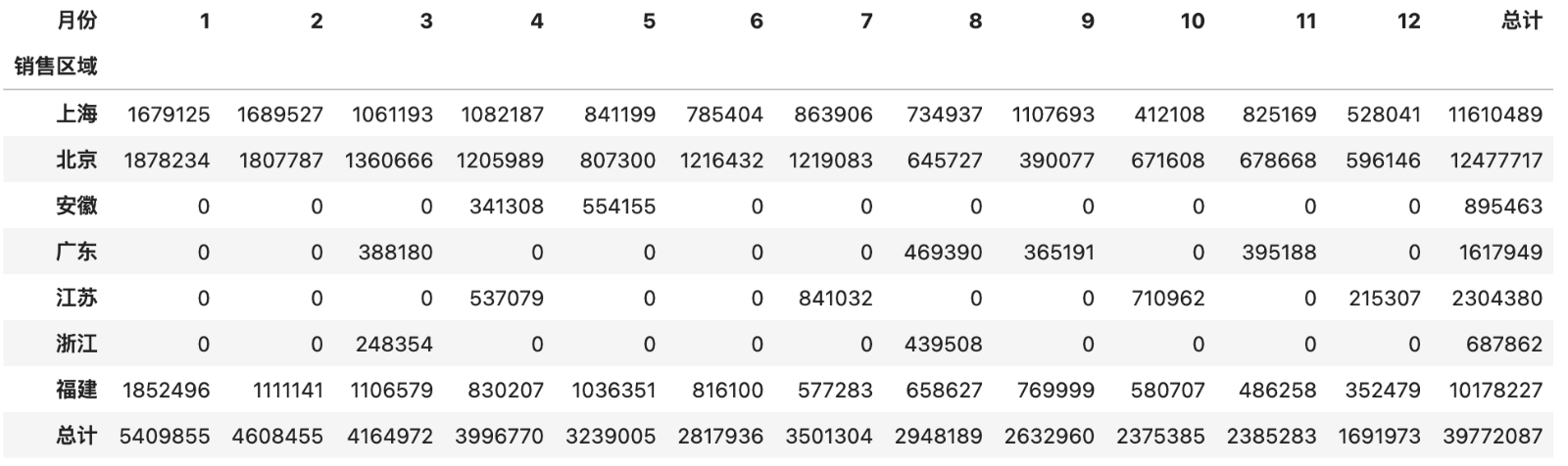
pd.pivot_table(df, index='销售区域', columns='月份', values='销售额', aggfunc='sum', fill_value=0)
说明:
pivot_table函数的fill_value=0会将空值处理为0。
输出:
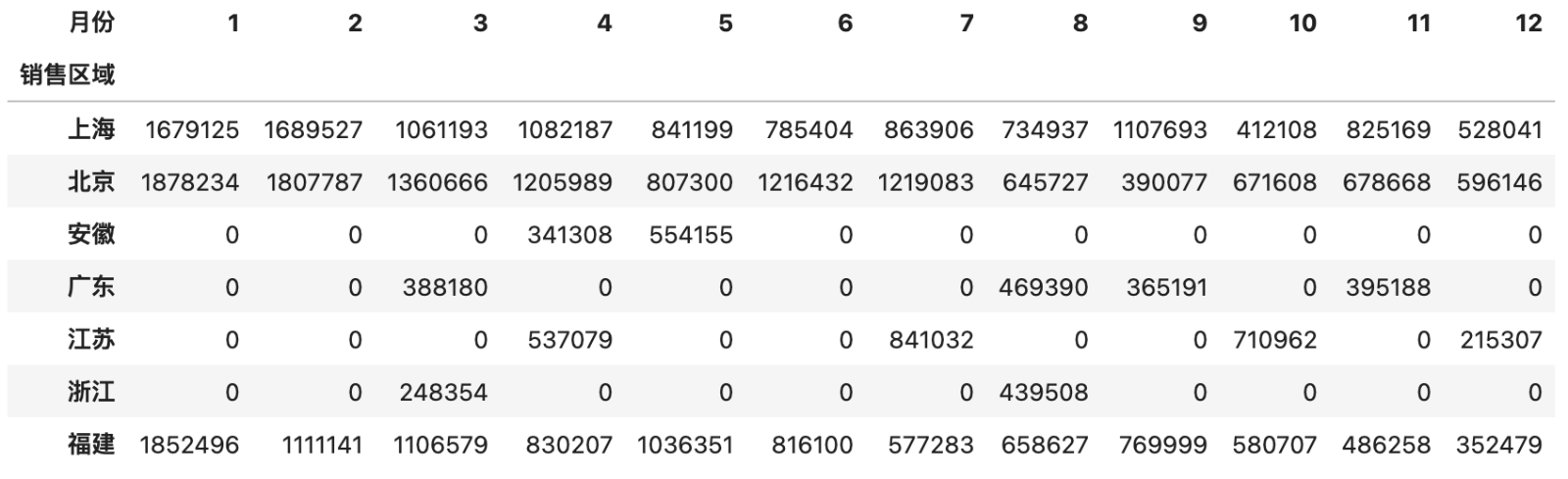
使用pivot_table函数时,还可以通过添加margins和margins_name参数对分组聚合的结果做一个汇总,具体的操作和效果如下所示。
pd.pivot_table(df, index='销售区域', columns='月份', values='销售额', aggfunc='sum', fill_value=0, margins=True, margins_name='总计')
输出:
交叉表就是一种特殊的透视表,它不需要先构造一个DataFrame对象,而是直接通过数组或Series对象指定两个或多个因素进行运算得到统计结果。例如,我们要统计每个销售区域的销售总额,也可以按照如下所示的方式来完成,我们先准备三组数据。
sales_area, sales_month, sales_amount = df['销售区域'], df['月份'], df['销售额']
使用crosstab函数生成交叉表。
pd.crosstab(index=sales_area, columns=sales_month, values=sales_amount, aggfunc='sum').fillna(0).astype('i8')说明:上面的代码使用了
DataFrame对象的fillna方法将空值处理为0,再使用astype方法将数据类型处理成整数。
数据呈现
一图胜千言,我们对数据进行透视的结果,最终要通过图表的方式呈现出来,因为图表具有极强的表现力,能够让我们迅速的解读数据中隐藏的价值。和Series一样,DataFrame对象提供了plot方法来支持绘图,底层仍然是通过matplotlib库实现图表的渲染。关于matplotlib的内容,我们在下一个章节进行详细的探讨,这里我们只简单的讲解plot方法的用法。
例如,我们想通过一张柱状图来比较“每个销售区域的销售总额”,可以直接在透视表上使用plot方法生成柱状图。我们先导入matplotlib.pyplot模块,通过修改绘图的参数使其支持中文显示。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'FZJKai-Z03S'
说明:上面的
FZJKai-Z03S是我电脑上已经安装的一种支持中文的字体的名称,字体的名称可以通过查看用户主目录下.matplotlib文件夹下名为fontlist-v330.json的文件来获得,而这个文件在执行上面的命令后就会生成。
使用魔法指令配置生成矢量图。
%config InlineBackend.figure_format = 'svg'
绘制“每个销售区域销售总额”的柱状图。
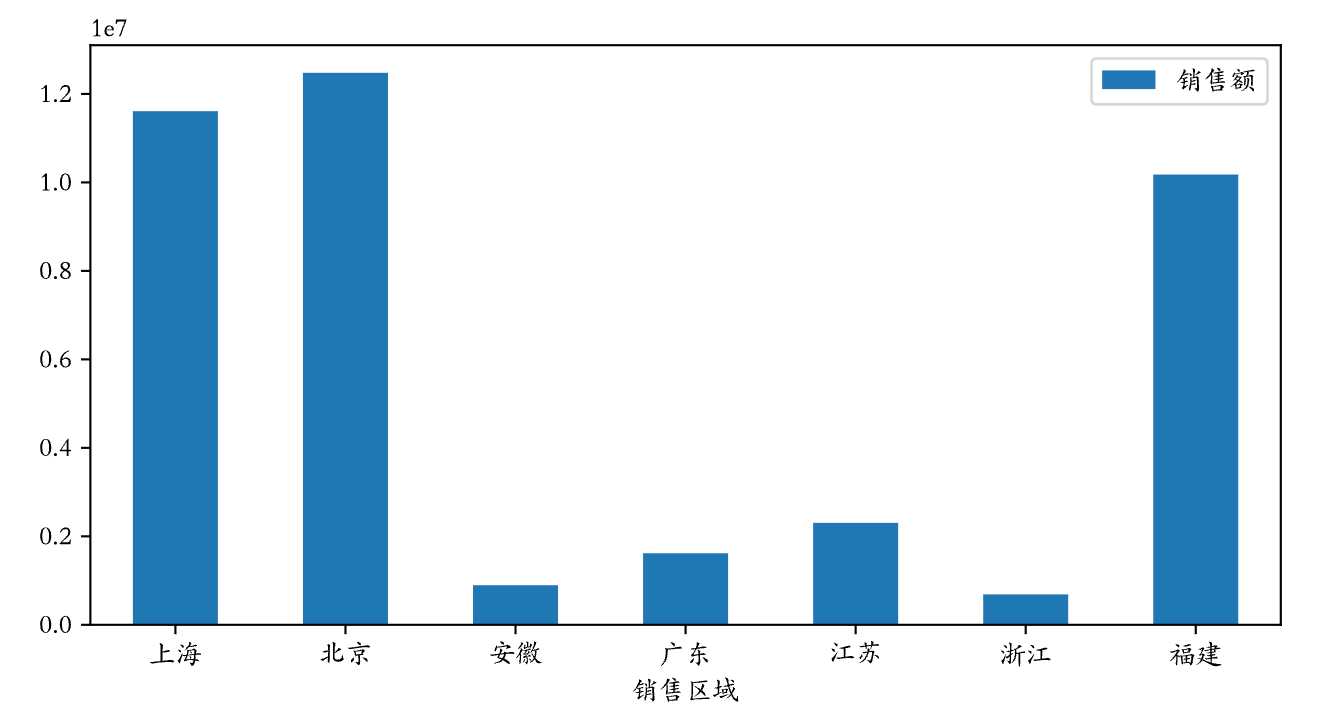
temp = pd.pivot_table(df, index='销售区域', values='销售额', aggfunc='sum')
temp.plot(figsize=(8, 4), kind='bar')
plt.xticks(rotation=0)
plt.show()
说明:上面的第3行代码会将横轴刻度上的文字旋转到0度,第4行代码会显示图像。
输出:
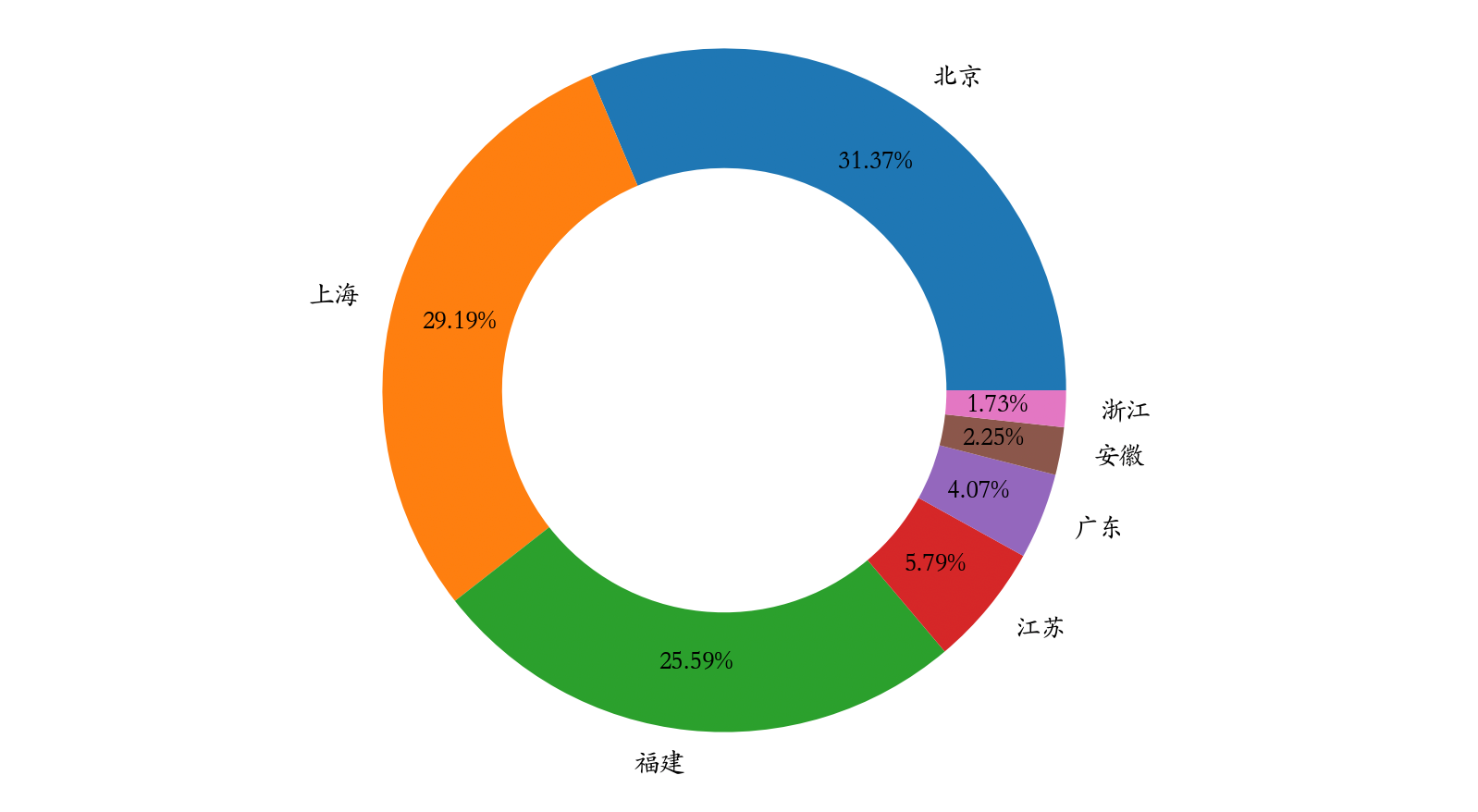
如果要绘制饼图,可以修改plot方法的kind参数为pie,然后使用定制饼图的参数对图表加以定制,代码如下所示。
temp.sort_values(by='销售额', ascending=False).plot(
figsize=(6, 6),
kind='pie',
y='销售额',
ylabel='',
autopct='%.2f%%',
pctdistance=0.8,
wedgeprops=dict(linewidth=1, width=0.35),
legend=False
)
plt.show()
输出:
我们再来补充一些使用DataFrame做数据分析时会使用到的操作,这些操作不仅常见而且也非常重要。
计算同比环比
我们之前讲过一个统计月度销售额的例子,我们可以通过groupby方法做分组聚合,也可以通过pivot_table生成透视表,如下所示。
sales_df = pd.read_excel('data/2020年销售数据.xlsx')
sales_df['月份'] = sales_df.销售日期.dt.month
sales_df['销售额'] = sales_df.售价 * sales_df.销售数量
result_df = sales_df.pivot_table(index='月份', values='销售额', aggfunc='sum')
result_df.rename(columns={'销售额': '本月销售额'}, inplace=True)
result_df
输出:
本月销售额
月份
1 5409855
2 4608455
3 4164972
4 3996770
5 3239005
6 2817936
7 3501304
8 2948189
9 2632960
10 2375385
11 2385283
12 1691973
在得到月度销售额之后,如果我们需要计算月环比,这里有两种方案。第一种方案是我们可以使用shift方法对数据进行移动,将上一个月的数据与本月数据对齐,然后通过(本月销售额 - 上月销售额) / 上月销售额来计算月环比,代码如下所示。
result_df['上月销售额'] = result_df.本月销售额.shift(1)
result_df
输出:
本月销售额 上月销售额
月份
1 5409855 NaN
2 4608455 5409855.0
3 4164972 4608455.0
4 3996770 4164972.0
5 3239005 3996770.0
6 2817936 3239005.0
7 3501304 2817936.0
8 2948189 3501304.0
9 2632960 2948189.0
10 2375385 2632960.0
11 2385283 2375385.0
12 1691973 2385283.0
在上面的例子中,shift方法的参数为1表示将数据向下移动一个单元,当然我们可以使用参数-1将数据向上移动一个单元。相信大家能够想到,如果我们有更多年份的数据,我们可以将参数设置为12,这样就可以计算今年的每个月与去年的每个月之间的同比。
result_df['环比'] = (result_df.本月销售额 - result_df.上月销售额) / result_df.上月销售额
result_df.style.format(
formatter={'上月销售额': '{:.0f}', '环比': '{:.2%}'},
na_rep='--------'
)
输出:
本月销售额 上月销售额 环比
月份
1 5409855 -------- --------
2 4608455 5409855 -14.81%
3 4164972 4608455 -9.62%
4 3996770 4164972 -4.04%
5 3239005 3996770 -18.96%
6 2817936 3239005 -13.00%
7 3501304 2817936 24.25%
8 2948189 3501304 -15.80%
9 2632960 2948189 -10.69%
10 2375385 2632960 -9.78%
11 2385283 2375385 0.42%
12 1691973 2385283 -29.07%
说明:使用 JupyterLab 时,可以通过
DataFrame对象的style属性在网页中对其进行渲染,上面的代码通过Styler对象的format方法将环比格式化为百分比进行显示,此外还指定了将空值替换为--------。
更为简单的第二种方案是直接使用pct_change方法计算变化的百分比,我们先将之前的上月销售额和环比列删除掉。
result_df.drop(columns=['上月销售额', '环比'], inplace=True)
接下来,我们使用DataFrame对象的pct_change方法完成环比的计算。值得一提的是,pct_change方法有一个名为periods的参数,它的默认值是1,计算相邻两项数据变化的百分比,这不就是我们想要的环比吗?如果我们有很多年的数据,在计算时把这个参数的值修改为12,就可以得到相邻两年的月同比。
result_df['环比'] = result_df.pct_change()
result_df
窗口计算
DataFrame对象的rolling方法允许我们将数据置于窗口中,然后用函数对窗口中的数据进行运算和处理。例如,我们获取了某只股票近期的数据,想制作5日均线和10日均线,那么就需要先设置窗口再进行运算。我们先用如下所示的代码读取2022年百度的股票数据,数据文件可以通过下面的链接来获取。
baidu_df = pd.read_excel('data/2022年股票数据.xlsx', sheet_name='BIDU')
baidu_df.sort_index(inplace=True)
baidu_df输出:
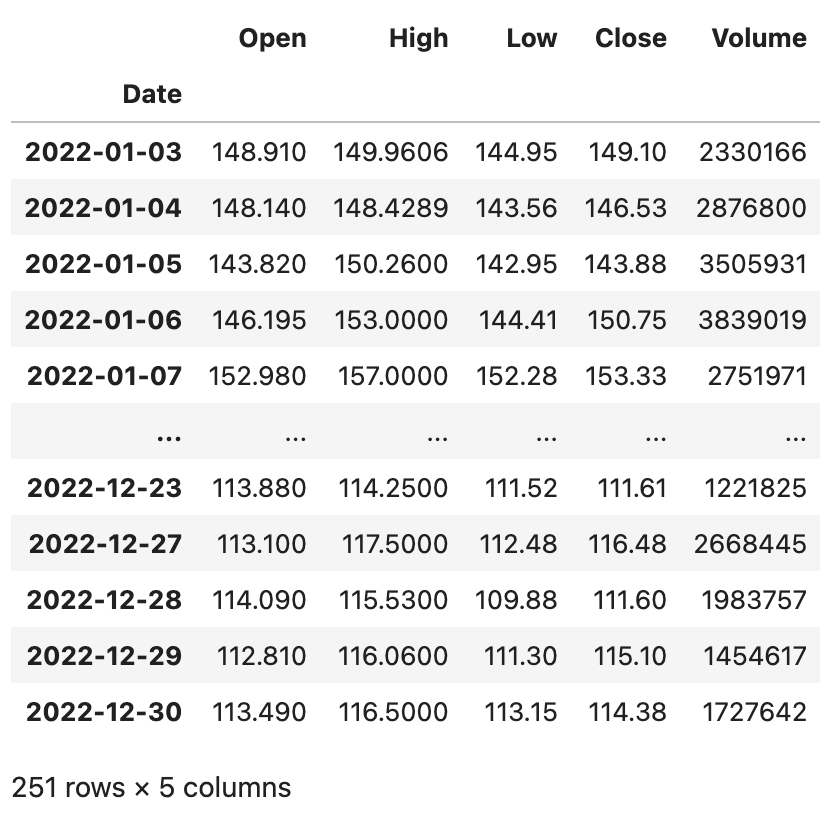
上面的DataFrame有Open、High、Low、Close、Volume五个列,分别代表股票的开盘价、最高价、最低价、收盘价和成交量,接下来我们对百度的股票数据进行窗口计算。
baidu_df.rolling(5).mean()
输出:
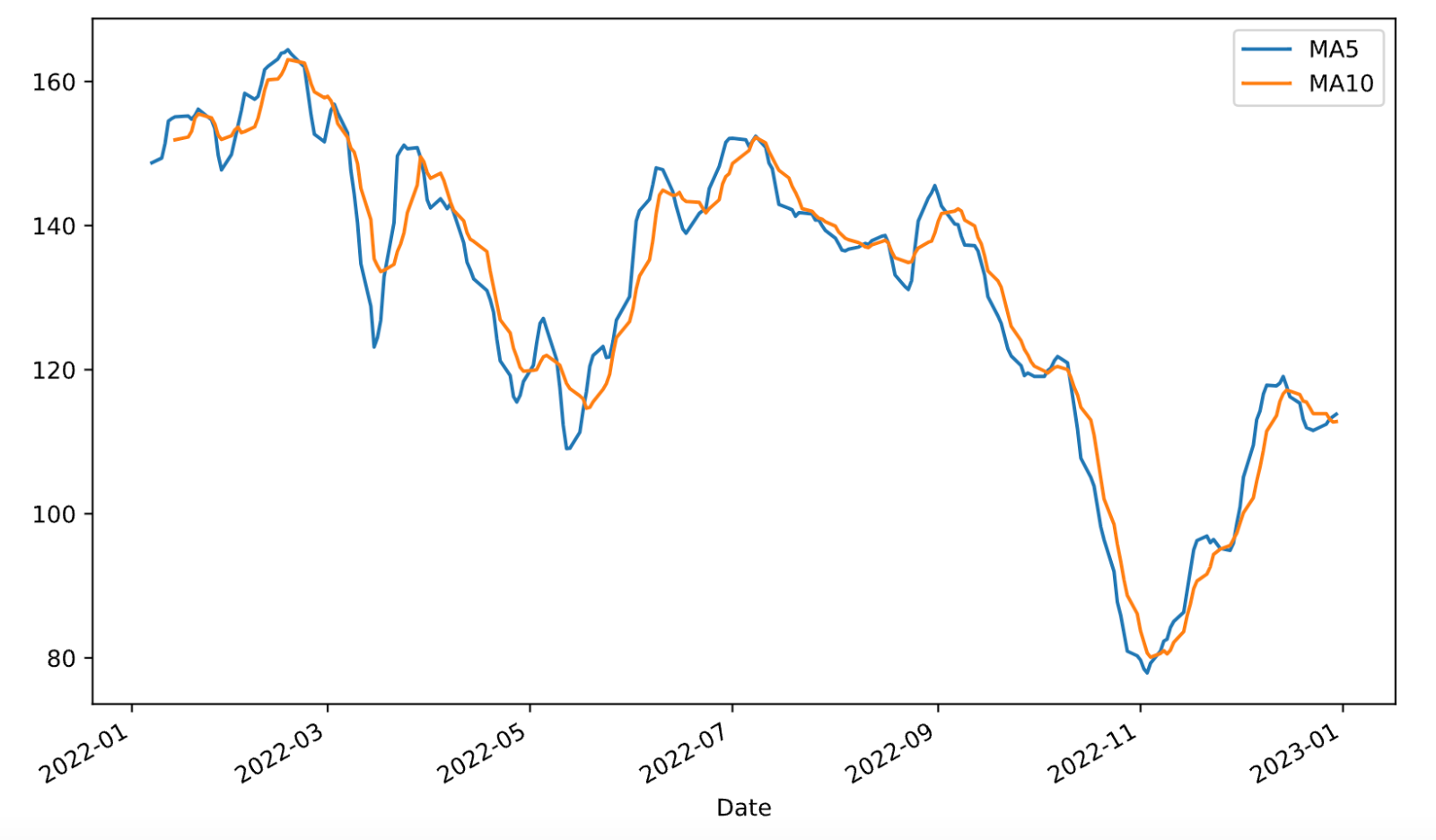
我们也可以在Series上使用rolling设置窗口并在窗口内完成运算,例如我们可以对上面的百度股票收盘价(Close列)计算5日均线和10日均线,并使用merge函数将其组装到一个DataFrame对象中并绘制出双均线图,代码如下所示。
close_ma5 = baidu_df.Close.rolling(5).mean()
close_ma10 = baidu_df.Close.rolling(10).mean()
result_df = pd.merge(close_ma5, close_ma10, left_index=True, right_index=True)
result_df.rename(columns={'Close_x': 'MA5', 'Close_y': 'MA10'}, inplace=True)
result_df.plot(kind='line', figsize=(10, 6))
plt.show()输出:
相关性判定
在统计学中,我们通常使用协方差(covariance)来衡量两个随机变量的联合变化程度。如果变量 $\small{X}$ 的较大值主要与另一个变量 $\small{Y}$ 的较大值相对应,而两者较小值也相对应,那么两个变量倾向于表现出相似的行为,协方差为正。如果一个变量的较大值主要对应于另一个变量的较小值,则两个变量倾向于表现出相反的行为,协方差为负。简单的说,协方差的正负号显示着两个变量的相关性。方差是协方差的一种特殊情况,即变量与自身的协方差。
%20%3D%20E((X%20-%20%5Cmu)(Y%20-%20%5Cupsilon))%20%3D%20E(X%20%5Ccdot%20Y)%20-%20%5Cmu%5Cupsilon)
如果 $\small{X}$ 和 $\small{Y}$ 是统计独立的,那么二者的协方差为 0,这是因为在 $\small{X}$ 和 $\small{Y}$ 独立的情况下:
%20%3D%20E(X)%20%5Ccdot%20E(Y)%20%3D%20%5Cmu%5Cupsilon)
协方差的数值大小取决于变量的大小,通常是不容易解释的,但是正态形式的协方差可以显示两变量线性关系的强弱。在统计学中,皮尔逊积矩相关系数就是正态形式的协方差,它用于度量两个变量 $\small{X}$ 和 $\small{Y}$ 之间的相关程度(线性相关),其值介于 -1 到 1 之间。
%7D%20%7B%5Csigma_%7BX%7D%5Csigma_%7BY%7D%7D)
估算样本的协方差和标准差,可以得到样本皮尔逊系数,通常用希腊字母 $\small{\rho}$ 表示。
(Y_i%20-%20%5Cbar%7BY%7D)%7D%20%7B%5Csqrt%7B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D(X_i%20-%20%5Cbar%7BX%7D)%5E2%7D%20%5Csqrt%7B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D(Y_i%20-%20%5Cbar%7BY%7D)%5E2%7D%7D)
我们用 $\small{\rho}$ 值判断指标的相关性时遵循以下两个步骤。
判断指标间是正相关、负相关,还是不相关。
当
 ,认为变量之间是正相关,也就是两者的趋势一致。
,认为变量之间是正相关,也就是两者的趋势一致。当
 ,认为变量之间是负相关,也就是两者的趋势相反。
,认为变量之间是负相关,也就是两者的趋势相反。当
 ,认为变量之间是不相关的,但并不代表两个指标是统计独立的。
,认为变量之间是不相关的,但并不代表两个指标是统计独立的。判断指标间的相关程度。
当
 的绝对值在
的绝对值在  之间,认为变量之间是强相关的。
之间,认为变量之间是强相关的。当
的绝对值在%7D) 之间,认为变量之间是弱相关的。
之间,认为变量之间是弱相关的。当
的绝对值在 %7D) 之间,认为变量之间没有相关性。
之间,认为变量之间没有相关性。
皮尔逊相关系数适用于:
两个变量之间是线性关系,都是连续数据。
两个变量的总体是正态分布,或接近正态的单峰分布。
两个变量的观测值是成对的,每对观测值之间相互独立。
这里,我们顺便说一下,如果两组变量并不是来自于正态总体的连续值,我们该如何判断相关性呢?对于定序尺度(等级),我们可以使用斯皮尔曼秩相关系数,其计算公式如下所示:
%7D%7D)
其中, -%5Coperatorname%20%7BR%7D%20(Y_%7Bi%7D)%7D) ,即每组观测中两个变量的等级差值,
,即每组观测中两个变量的等级差值, 为观测样本数。
为观测样本数。
对于定类尺度(类别),我们可以使用卡方检验的方式来判定其是否相关。其实很多时候,连续值也可以通过分箱的方式处理成离散的等级或类别,然后使用斯皮尔曼秩相关系数或卡方检验的方式来判定相关性。
DataFrame对象的cov方法和corr方法分别用于计算协方差和相关系数,corr方法有一个名为method的参数,其默认值是pearson,表示计算皮尔逊相关系数;除此之外,还可以指定kendall或spearman来计算肯德尔系数或斯皮尔曼秩相关系数。
我们从名为boston_house_price.csv的文件中获取著名的波士顿房价数据集来创建一个DataFrame。
boston_df = pd.read_csv('data/boston_house_price.csv')
boston_df输出:
说明:上面代码中使用了相对路径来访问 CSV 文件,也就是说 CSV 文件在当前工作路径下名为
data的文件夹中。如果需要上面例子中的 CSV 文件,可以通过下面的百度云盘地址进行获取。链接:https://pan.baidu.com/s/1rQujl5RQn9R7PadB2Z5g_g?pwd=e7b4,提取码:e7b4。
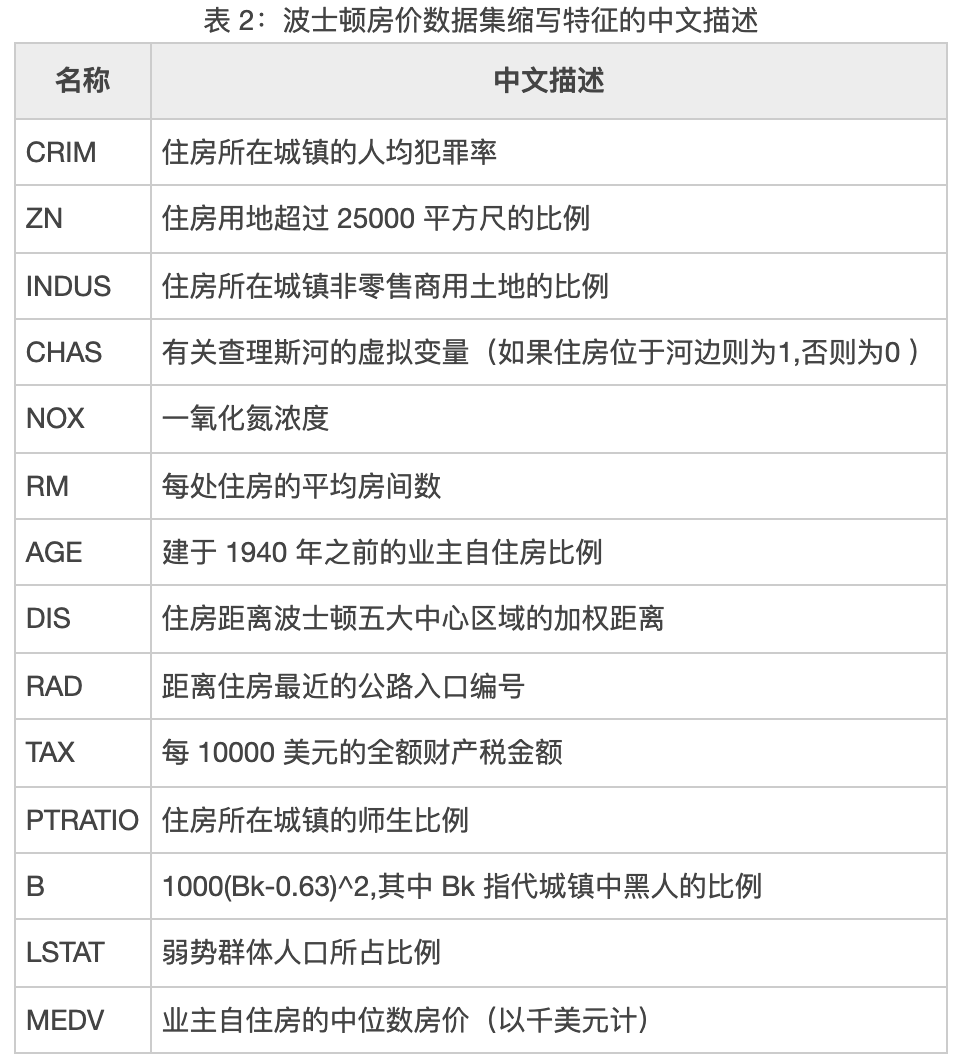
可以看出,该数据集中包含了诸多影响房价的特征,包括犯罪率、一氧化氮浓度、平均房间数、低收入人群占比等,其中PRICE代表房价,具体情况如下所示。
接下来,我们将其中可以视为来自于正态总体的连续值,通过corr方法计算皮尔逊相关系数,看看哪些跟房价是正相关或负相关的关系,代码如下所示。
boston_df[['NOX', 'RM', 'PTRATIO', 'LSTAT', 'PRICE']].corr()
输出:
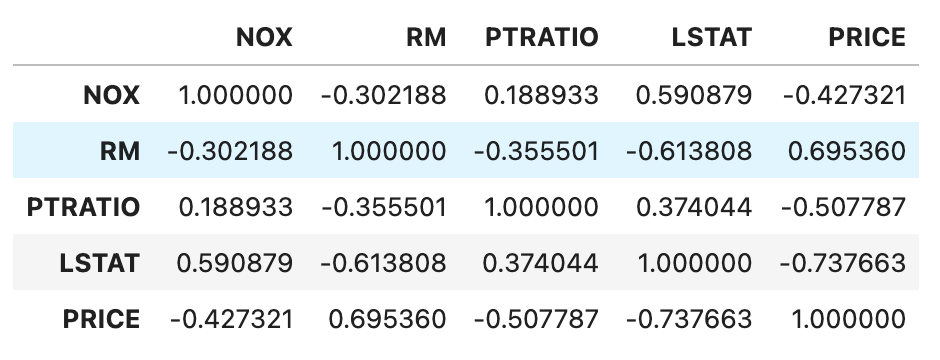
可以看出,平均房间数(RM)跟房价有较强的正相关性,而低收入人群占比(LSTAT)跟房价之间存在明显的负相关性。
斯皮尔曼秩相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级数据,或者是由连续变量转化成等级的数据,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。我们可以通过下面的方式对部分特征进行预处理,然后计算斯皮尔曼秩相关系数。
boston_df['CRIM'] = boston_df.CRIM.apply(lambda x: x // 5 if x < 25 else 5).map(int) boston_df['ZN'] = pd.qcut(boston_df.ZN, q=[0, 0.75, 0.8, 0.85, 0.9, 0.95, 1], labels=np.arange(6)) boston_df['AGE'] = (boston_df.AGE // 20).map(int) boston_df['DIS'] = (boston_df.DIS // 2.05).map(int) boston_df['B'] = (boston_df.B // 66).map(int) boston_df['PRICE'] = pd.qcut(boston_df.PRICE, q=[0, 0.15, 0.3, 0.5, 0.7, 0.85, 1], labels=np.arange(6)) boston_df[['CRIM', 'ZN', 'AGE', 'DIS', 'B', 'PRICE']].corr(method='spearman')
输出:
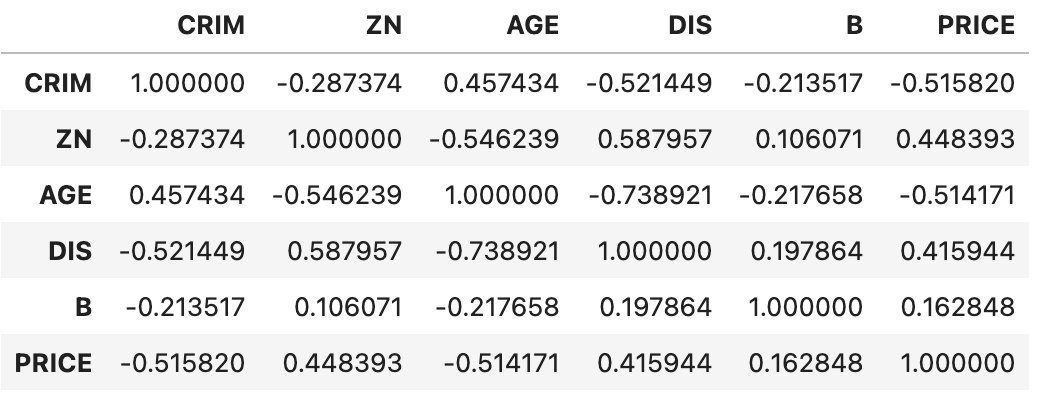
可以看出,房价跟犯罪率(CRIM)和房龄(AGE)之间存在较为明显的负相关关系,跟住房用地尺寸(ZN)存在微弱的正相关关系。相关性可以帮助我们在实际工作中找到业务抓手,即找到那些能够影响或改变工作结果的相关因素。
我们再来看看Index类型,它为Series和DataFrame对象提供了索引服务,有了索引我们就可以排序数据(sort_index方法)、对齐数据(在运算和合并数据时非常重要)并实现对数据的快速检索(索引运算)。由于DataFrame类型表示的是二维数据,所以它的行和列都有索引,分别是index和columns。Index类型的创建的比较简单,通常给出data、dtype和name三个参数即可,分别表示作为索引的数据、索引的数据类型和索引的名称。由于Index本身也是一维的数据,索引它的方法和属性跟Series非常类似,你可以尝试创建一个Index对象,然后尝试一下之前学过的属性和方法在Index类型上是否生效。接下来,我们主要看看Index的几种子类型。
范围索引
范围索引是由具有单调性的整数构成的索引,我们可以通过RangeIndex构造器来创建范围索引,也可以通过RangeIndex类的类方法from_range来创建范围索引,代码如下所示。
代码:
sales_data = np.random.randint(400, 1000, 12)
index = pd.RangeIndex(1, 13, name='月份')
ser = pd.Series(data=sales_data, index=index)
ser
输出:
月份
1 703
2 705
3 557
4 943
5 961
6 615
7 788
8 985
9 921
10 951
11 874
12 609
dtype: int64
分类索引
分类索引是由定类尺度构成的索引。如果我们需要通过索引将数据分组,然后再进行聚合操作,分类索引就可以派上用场。分类索引还有一个名为reorder_categories的方法,可以给索引指定一个顺序,分组聚合的结果会按照这个指定的顺序进行呈现,代码如下所示。
代码:
sales_data = [6, 6, 7, 6, 8, 6]
index = pd.CategoricalIndex(
data=['苹果', '香蕉', '苹果', '苹果', '桃子', '香蕉'],
categories=['苹果', '香蕉', '桃子'],
ordered=True
)
ser = pd.Series(data=sales_data, index=index)
ser
输出:
苹果 6
香蕉 6
苹果 7
苹果 6
桃子 8
香蕉 6
dtype: int64
基于索引分组数据,然后使用sum进行求和。
ser.groupby(level=0).sum()
输出:
苹果 19
香蕉 12
桃子 8
dtype: int64
指定索引的顺序。
ser.index = index.reorder_categories(['香蕉', '桃子', '苹果'])
ser.groupby(level=0).sum()
输出:
香蕉 12
桃子 8
苹果 19
dtype: int64
多级索引
Pandas 中的MultiIndex类型用来表示层次或多级索引。可以使用MultiIndex类的类方法from_arrays、from_product、from_tuples等来创建多级索引,我们给大家举几个例子。
代码:
tuples = [(1, 'red'), (1, 'blue'), (2, 'red'), (2, 'blue')] index = pd.MultiIndex.from_tuples(tuples, names=['no', 'color']) index
输出:
MultiIndex([(1, 'red'), (1, 'blue'), (2, 'red'), (2, 'blue')], names=['no', 'color'])
代码:
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']] index = pd.MultiIndex.from_arrays(arrays, names=['no', 'color']) index
输出:
MultiIndex([(1, 'red'), (1, 'blue'), (2, 'red'), (2, 'blue')], names=['no', 'color'])
代码:
sales_data = np.random.randint(1, 100, 4) ser = pd.Series(data=sales_data, index=index) ser
输出:
no color 1 red 43 blue 31 2 red 55 blue 75 dtype: int64
代码:
ser.groupby('no').sum()输出:
no 1 74 2 130 dtype: int64
代码:
ser.groupby(level=1).sum()
输出:
color blue 106 red 98 dtype: int64
代码:
stu_ids = np.arange(1001, 1006) semisters = ['期中', '期末'] index = pd.MultiIndex.from_product((stu_ids, semisters), names=['学号', '学期']) courses = ['语文', '数学', '英语'] scores = np.random.randint(60, 101, (10, 3)) df = pd.DataFrame(data=scores, columns=courses, index=index) df
输出:
语文 数学 英语 学号 学期 1001 期中 93 77 60 期末 93 98 84 1002 期中 64 78 71 期末 70 71 97 1003 期中 72 88 97 期末 99 100 63 1004 期中 80 71 61 期末 91 62 72 1005 期中 82 95 67 期末 84 78 86
根据第一级索引分组数据,按照期中成绩占25%,期末成绩占75% 的方式计算每个学生每门课的成绩。
代码:
df.groupby(level=0).agg(lambda x: x.values[0] * 0.25 + x.values[1] * 0.75)
输出:
语文 数学 英语 学号 1001 93.00 92.75 78.00 1002 68.50 72.75 90.50 1003 92.25 97.00 71.50 1004 88.25 64.25 69.25 1005 83.50 82.25 81.25
间隔索引
间隔索引顾名思义是使用固定的间隔范围充当索引,我们通常会使用interval_range函数来创建间隔索引,代码如下所示。
代码:
index = pd.interval_range(start=0, end=5) index
输出:
IntervalIndex([(0, 1], (1, 2], (2, 3], (3, 4], (4, 5]], dtype='interval[int64, right]')
IntervalIndex有一个名为contains的方法,可以检查范围内是否包含了某个元素,如下所示。
代码:
index.contains(1.5)
输出:
array([False, True, False, False, False])
IntervalIndex还有一个名为overlaps的方法,可以检查一个范围跟其他的范围是否有重叠,如下所示。
代码:
index.overlaps(pd.Interval(1.5, 3.5))
输出:
array([False, True, True, True, False])
如果希望间隔范围是左闭右开的状态,可以在创建间隔索引时通过closed='left'来做到;如果希望两边都是关闭状态,可以将close参数的值赋值为both,代码如下所示。
代码:
index = pd.interval_range(start=0, end=5, closed='left') index
输出:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5)], dtype='interval[int64, left]')
代码:
index = pd.interval_range(start=pd.Timestamp('2022-01-01'), end=pd.Timestamp('2022-01-04'), closed='both')
index输出:
IntervalIndex([[2022-01-01, 2022-01-02], [2022-01-02, 2022-01-03], [2022-01-03, 2022-01-04]], dtype='interval[datetime64[ns], both]')
日期时间索引
DatetimeIndex应该是众多索引中最复杂最重要的一种索引,我们通常会使用date_range()函数来创建日期时间索引,该函数有几个非常重要的参数start、end、periods、freq、tz,分别代表起始日期时间、结束日期时间、生成周期、采样频率和时区。我们先来看看如何创建DatetimeIndex对象,再来讨论它的相关运算和操作,代码如下所示。
代码:
pd.date_range('2021-1-1', '2021-6-30', periods=10)输出:
DatetimeIndex(['2021-01-01', '2021-01-21', '2021-02-10', '2021-03-02', '2021-03-22', '2021-04-11', '2021-05-01', '2021-05-21', '2021-06-10', '2021-06-30'], dtype='datetime64[ns]', freq=None)
代码:
pd.date_range('2021-1-1', '2021-6-30', freq='W')说明:
freq=W表示采样周期为一周,它会默认星期日是一周的开始;如果你希望星期一表示一周的开始,你可以将其修改为freq=W-MON;你也可以试着将该参数的值修改为12H,M,Q等,看看会发生什么,相信你不难猜到它们的含义。
输出:
DatetimeIndex(['2021-01-03', '2021-01-10', '2021-01-17', '2021-01-24', '2021-01-31', '2021-02-07', '2021-02-14', '2021-02-21', '2021-02-28', '2021-03-07', '2021-03-14', '2021-03-21', '2021-03-28', '2021-04-04', '2021-04-11', '2021-04-18', '2021-04-25', '2021-05-02', '2021-05-09', '2021-05-16', '2021-05-23', '2021-05-30', '2021-06-06', '2021-06-13', '2021-06-20', '2021-06-27'], dtype='datetime64[ns]', freq='W-SUN')
DatatimeIndex可以跟DateOffset类型进行运算,这一点很好理解,以为我们可以设置一个时间差让时间向前或向后偏移,具体的操作如下所示。
代码:
index = pd.date_range('2021-1-1', '2021-6-30', freq='W')
index - pd.DateOffset(days=2)输出:
DatetimeIndex(['2021-01-01', '2021-01-08', '2021-01-15', '2021-01-22', '2021-01-29', '2021-02-05', '2021-02-12', '2021-02-19', '2021-02-26', '2021-03-05', '2021-03-12', '2021-03-19', '2021-03-26', '2021-04-02', '2021-04-09', '2021-04-16', '2021-04-23', '2021-04-30', '2021-05-07', '2021-05-14', '2021-05-21', '2021-05-28', '2021-06-04', '2021-06-11', '2021-06-18', '2021-06-25'], dtype='datetime64[ns]', freq=None)
代码:
index + pd.DateOffset(hours=2, minutes=10)
输出:
DatetimeIndex(['2021-01-03 02:10:00', '2021-01-10 02:10:00', '2021-01-17 02:10:00', '2021-01-24 02:10:00', '2021-01-31 02:10:00', '2021-02-07 02:10:00', '2021-02-14 02:10:00', '2021-02-21 02:10:00', '2021-02-28 02:10:00', '2021-03-07 02:10:00', '2021-03-14 02:10:00', '2021-03-21 02:10:00', '2021-03-28 02:10:00', '2021-04-04 02:10:00', '2021-04-11 02:10:00', '2021-04-18 02:10:00', '2021-04-25 02:10:00', '2021-05-02 02:10:00', '2021-05-09 02:10:00', '2021-05-16 02:10:00', '2021-05-23 02:10:00', '2021-05-30 02:10:00', '2021-06-06 02:10:00', '2021-06-13 02:10:00', '2021-06-20 02:10:00', '2021-06-27 02:10:00'], dtype='datetime64[ns]', freq=None)
如果Series对象或DataFrame对象使用了DatetimeIndex类型的索引,此时我们可以通过asfreq()方法指定一个时间频率来实现对数据的抽样,我们仍然以之前讲过的百度股票数据为例,给大家做一个演示。
代码:
baidu_df = pd.read_excel('data/2022年股票数据.xlsx', sheet_name='BIDU', index_col='Date')
baidu_df.sort_index(inplace=True)
baidu_df.asfreq('5D')输出:
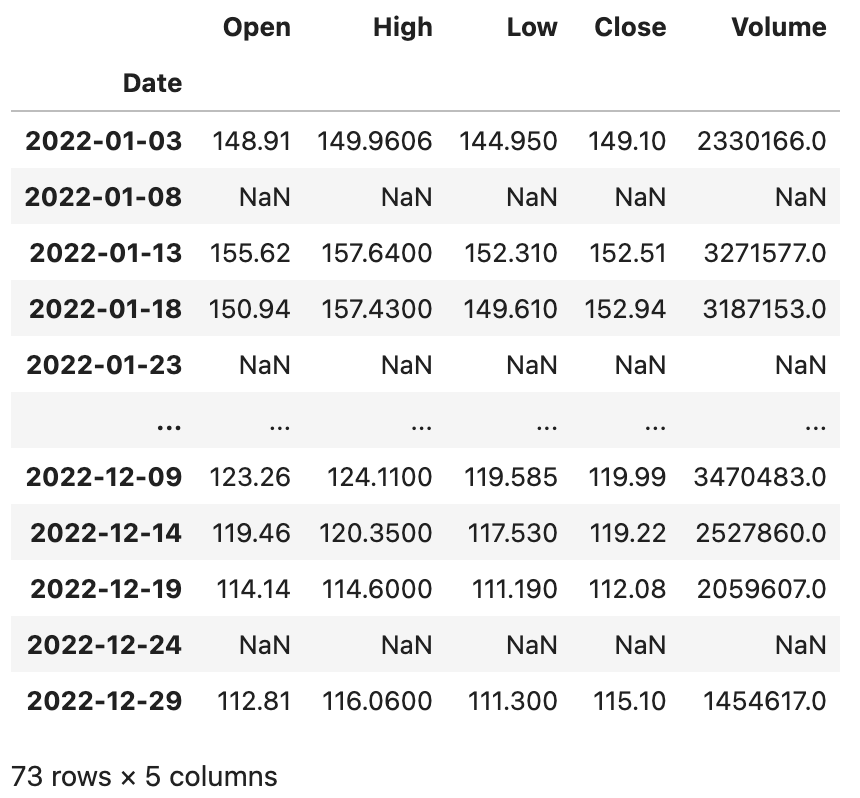
大家可能注意到了,每5天抽取1天有可能会抽中非交易日,那么对应的列都变成了空值,为了解决这个问题,在使用asfreq方法时可以通过method参数来指定一种填充空值的方法,可以将相邻的交易日的数据填入进来。
代码:
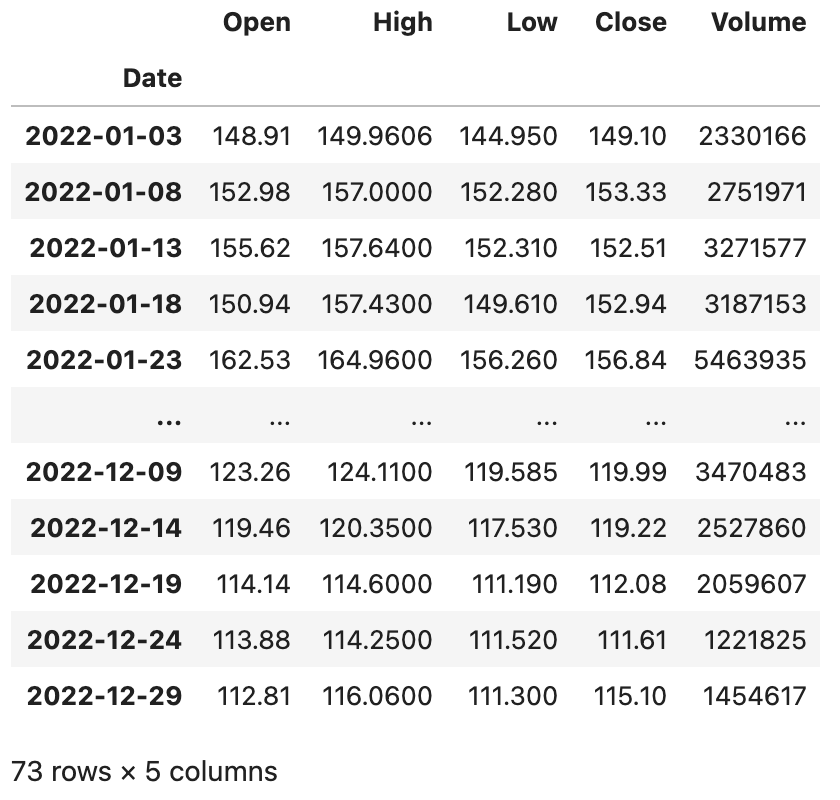
baidu_df.asfreq('5D', method='ffill')输出:
当使用DatetimeIndex索引时,我们也可以通过resample()方法基于时间对数据进行重采样,相当于根据时间周期对数据进行了分组操作,分组之后还可以进行聚合统计,代码如下所示。
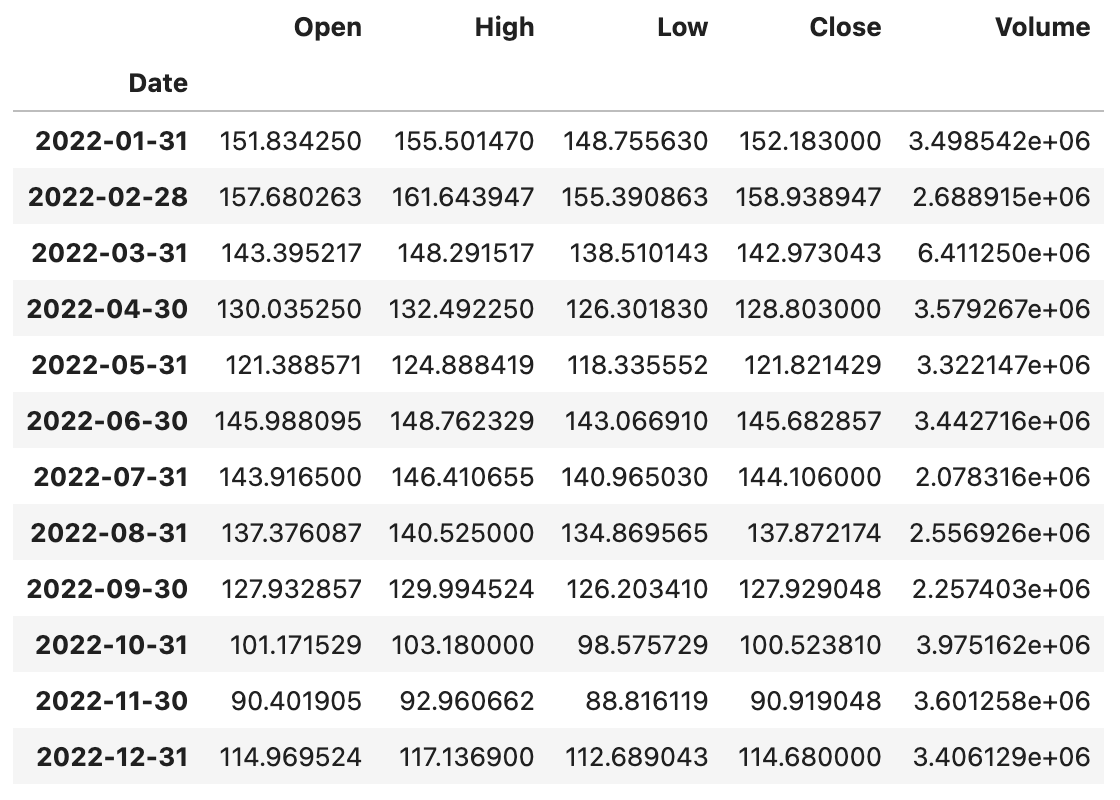
代码:
baidu_df.resample('1M').mean()输出:
代码:
baidu_df.resample('1M').agg(['mean', 'std'])输出:
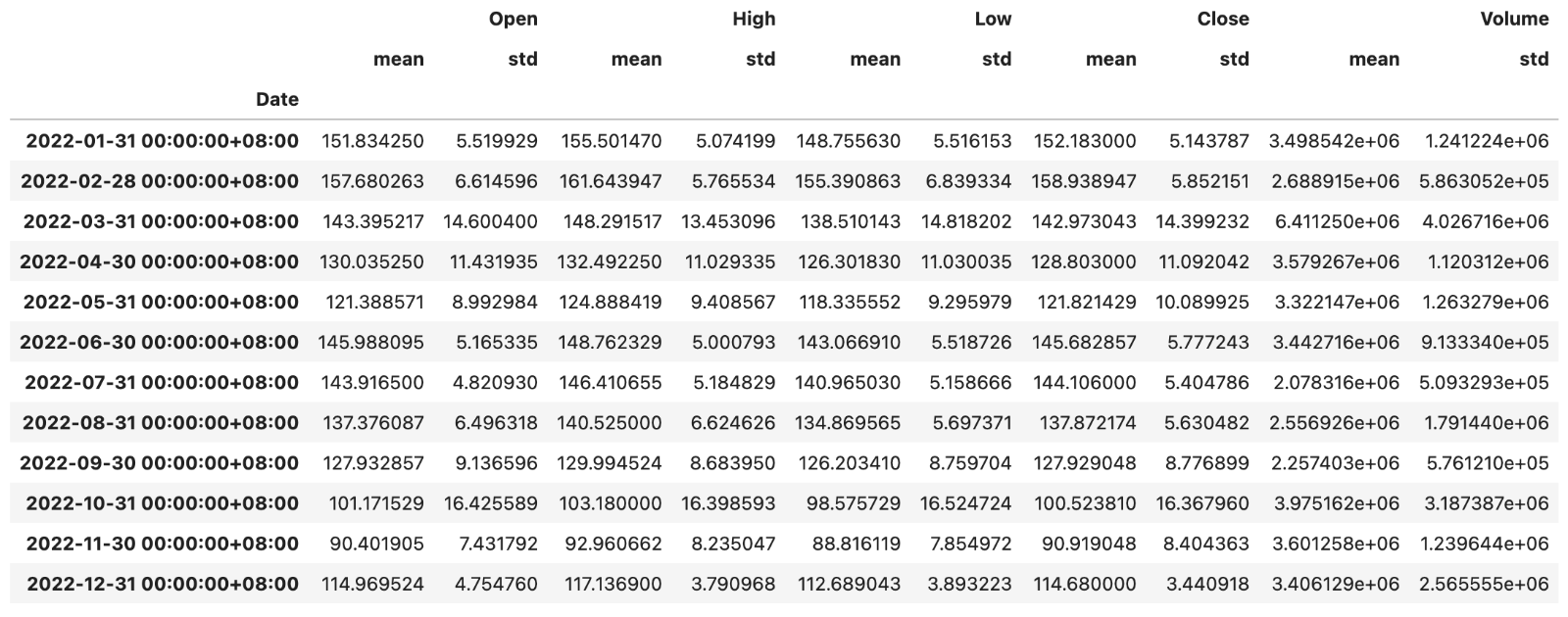
提示:不知大家是否注意到,上面输出的
DataFrame的列索引是一个MultiIndex对象。你可以访问上面的DataFrame对象的columns属性看看。
如果要实现日期时间的时区转换,我们可以先用tz_localize()方法将日期时间本地化,代码如下所示。
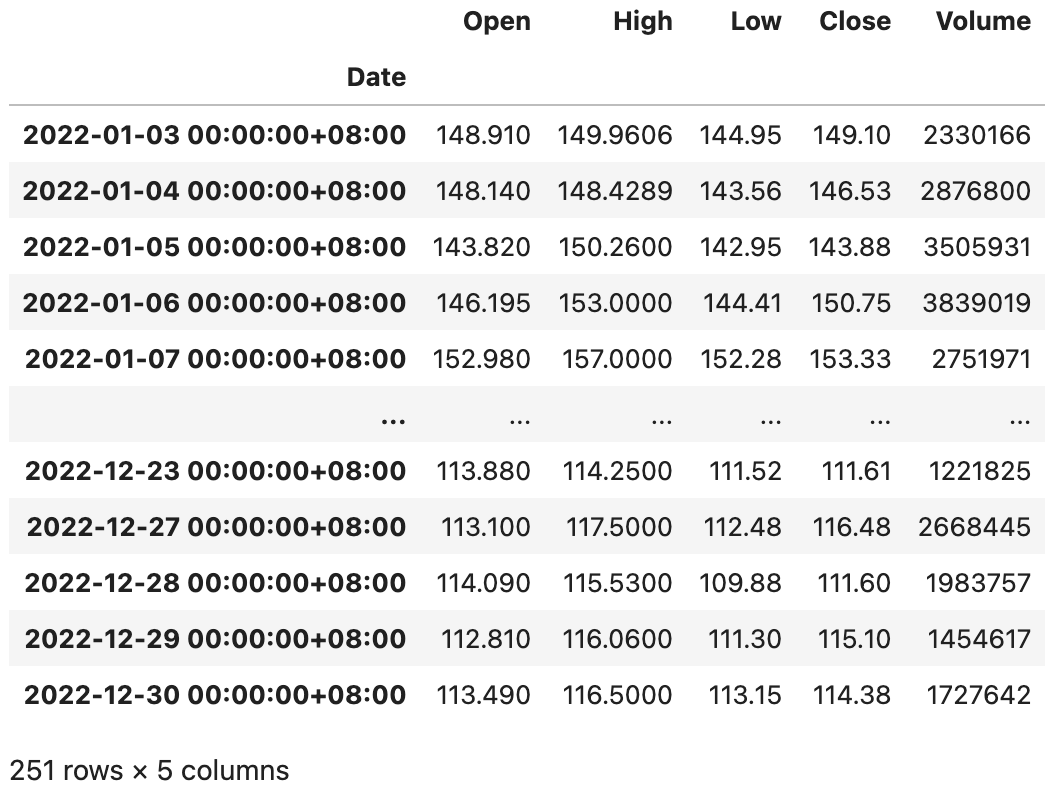
代码:
baidu_df = baidu_df.tz_localize('Asia/Chongqing')
baidu_df输出:
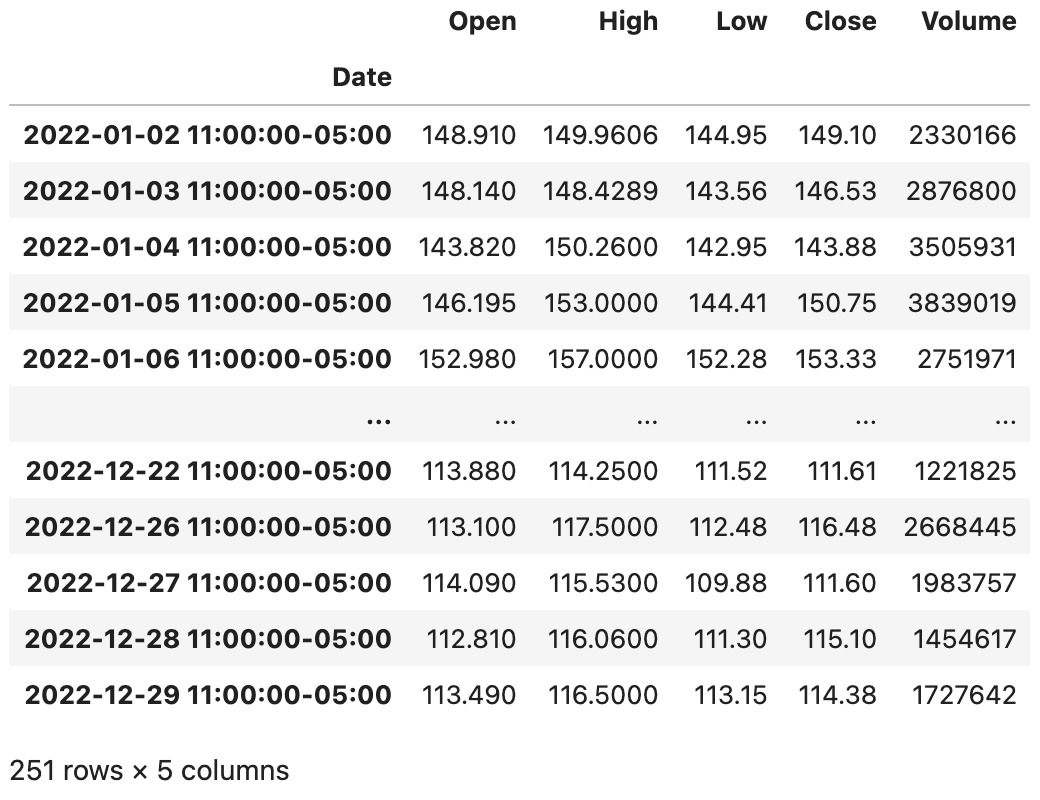
在对时间本地化以后,我们再使用tz_convert()方法就可以实现转换时区,代码如下所示。
代码:
baidu_df.tz_convert('America/New_York')输出:
如果你的数据使用了DatetimeIndex
评论