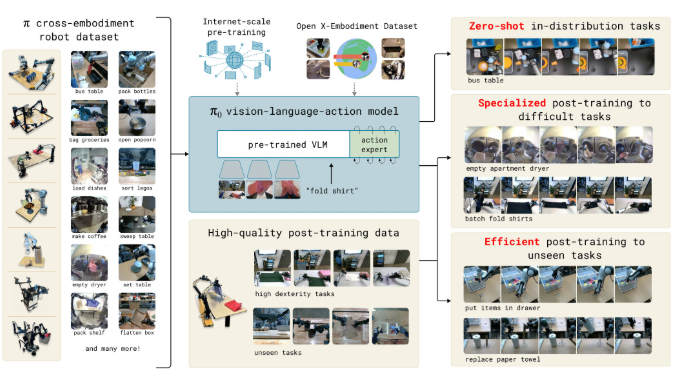
Pi0原理介绍一、Pi0 简介下面的原理介绍,基于 Pi0 论文,知识点较多,如果有谬误,欢迎反馈。论文地址:https://arxiv.org/pdf/2410.24164v1项目官网:https://www.physicalintelligence.company/blog/pi0我们使用的代码库:https://github.com/Physical-Intelligence/openpiblankπ0 是一个通用机器人策略模型(机器人基础模型),旨在解决机器人学习中的三大核心挑战:数据稀缺、泛化能力不足和鲁棒性问题。该模型采用类似大语言模型的训练范式,通过大规模预训练获得广泛的机器人操作能力,然后通过后训练适应特定任务。主要特点:支持零样本控制和语言指令跟随能够处理复杂的多阶段任务(如叠衣服、收拾桌子、组装盒子等)支持跨实体部署(7 种不同机器人配置)具备高频率精密操作能力(最高


Pi0原理介绍
一、Pi0 简介
下面的原理介绍,基于 Pi0 论文,知识点较多,如果有谬误,欢迎反馈。
论文地址:
项目官网:
我们使用的代码库:
blank
π0 是一个通用机器人策略模型(机器人基础模型),旨在解决机器人学习中的三大核心挑战:数据稀缺、泛化能力不足和鲁棒性问题。该模型采用类似大语言模型的训练范式,通过大规模预训练获得广泛的机器人操作能力,然后通过后训练适应特定任务。
主要特点:
支持零样本控制和语言指令跟随
能够处理复杂的多阶段任务(如叠衣服、收拾桌子、组装盒子等)
支持跨实体部署(7 种不同机器人配置)
具备高频率精密操作能力(最高 50Hz)
1.1 核心创新点
1.1.1 核心思想层面
范式转变
从专用到通用:机器人学习正在经历类似 NLP 领域的范式转变
规则驱动 → 统计方法 → 深度学习 → 预训练 + 微调 → 大模型时代 (1950s-80s) (1990s-2000s) (2010s 初) (2018-2020) (2020 至今)
Foundation Model 思维:大规模预训练 → 任务适配的两阶段范式
跨模态融合:视觉 + 语言 + 动作的统一建模思路
解决方案的设计
数据稀缺 → 大规模多样化数据
泛化不足 → 跨实体训练
鲁棒性差 → 预训练学恢复,后训练学精确
1.1.2 架构创新
VLM+ 流匹配融合:首次将预训练视觉语言模型与流匹配技术结合,既继承了互联网规模的语义知识,又能生成高质量连续动作分布
Action Expert 设计:引入专门的动作专家模块处理机器人状态和动作,与 VLM 骨干网络形成混合专家架构
为什么是 VLM + 流匹配?
VLM:继承语义理解能力
流匹配:生成高质量连续动作
Action Expert:专门处理机器人特有信息
后文有更深入介绍
1.1.3 训练策略创新
预训练阶段:借鉴 LLM 训练策略,预训练获得广泛能力,追求覆盖面,包含错误和恢复行为
后训练阶段:后训练实现任务专化,追求执行质量,展示最优策略
跨实体训练:单一模型支持 7 种不同机器人配置,实现真正的通用性
大规模数据融合:结合自收集的 10,000 小时精密操作数据和开源数据集
建议学习 Pi0 的时候,更多的关注范式转变的意义,毕竟网络架构可以千差万别,但范式的意义更加深远和持久。
可参考附录三:范式 VS 技术
二、网络架构
3.1 整体架构

左侧数据来源:
π 数据集:自收集的机器人操作数据
互联网预训练:大规模网络数据
OXE:开源机器人数据集
中间核心架构——预训练 VLM(视觉语言模型)
SigLIP (400M 参数) + Gemma (2.6B 参数)
多个 ViT(视觉变换器)模块处理视觉输入
支持语言指令(如"fold shirt" - 折衬衫)
右侧动作生成:
动作专家(
Action expert)模块 (300M 参数)生成动作序列(
Action Chunk):a_t, a_{t+1}, ..., a_{t+H}查询机制:
q_t噪声注入用于训练
支持的机器人平台:
14 自由度双臂操作器
18 自由度移动操作器
7 和 8 自由度单臂操作器
3.2 关键组件
π0 采用"VLM 骨干网络 + Action Expert"的混合专家架构,总参数量 3.3B:
$$
\pi_0 = \text{PaliGemma}(3B) + \text{Action Expert}(300M)
$$
3.2.1 VLM 骨干网络 (PaliGemma)
可参考附录一:VLM
作用与意义
继承互联网规模知识:从大规模图像-文本数据中学到的语义理解能力
处理多模态输入:融合视觉和语言信息
提供通用表示:为机器人任务提供强大的特征基础
具体配置
PaliGemma配置:
- 基于Gemma 2B语言模型
- 多查询注意力机制 (Multi-Query Attention)
- {width=2048, depth=18, mlp_dim=16384,
num_heads=18, num_kv_heads=1, head_dim=256}
输入处理
图像序列: $[I^1_t, I^2_t, I^3_t]$ → ViT 编码 → 线性投影到嵌入空间
原始输入: 3 张摄像头图像 (比如左、中、右视角) ↓ ViT 编码: 每张图像 → 一堆图像特征向量 (比如 256 个 patch 的特征) ↓ 线性投影: 将 ViT 的输出维度调整到与语言模型一致 (都变成 2048 维)
语言指令: $\ell_t$ → 标准
tokenization→ 词嵌入原始输入: "pick up the red cup" ↓ Tokenization: ["pick", "up", "the", "red", "cup"] (分词) ↓ 词嵌入: 每个词 → 2048 维向量
为什么要这样处理?
统一表示:最终图像特征和文字特征都变成相同维度的向量(多模态),这样 transformer 就能:
把它们放在同一个序列里
用注意力机制让它们互相"对话"
让模型理解"红色杯子在图像的哪个位置"
实际效果:模型能同时"看到"环境和"理解"指令,然后决定怎么移动机器人手臂。
3.2.2. Action Expert
在上图可以看到清晰的分工:
π0架构 = {
VLM骨干网络: 处理[图像, 语言] → 3B参数
Action Expert: 处理[状态, 动作] → 300M参数
交互方式: 通过self-attention层连接
}
设计动机
论文发现将机器人特定的 token 路由到专门的权重模块能显著提升性能,这是受到 Mixture of Experts 启发的设计。
架构细节
Action Expert配置:
- 参数量: ~300M (为了推理速度优化)
- {width=1024, mlp_dim=4096} # 比VLM骨干更紧凑
- 处理对象: [机器人状态q_t, 噪声动作A^τ_t]
输入处理
输入 1: 机器人状态$q_t=[关节角度1, 关节角度2, ..., 关节角度n]$
输入 2: 噪声动作 $A^τ_t$
专门优化
推理效率: 较小的参数量减少流匹配推理时间
任务特化: 专门学习动作-状态的映射关系
独立初始化: 从头开始训练,不受 VLM 预训练约束
3.2.3. 流匹配机制 (Flow Matching)
流匹配是 Diffusion 扩散模型的"简化高效版",特别适合需要实时响应和高精度的机器人控制任务。关于扩散模型:请参考
附录三:Diffusion policy
为什么需要流匹配?——如何让机器人生成高质量的连续动作?
传统方法的局限
离散化方法:将连续动作离散化为 token,但会损失精度
简单回归:直接预测动作均值,无法捕捉动作分布的复杂性
低频控制:难以实现高频率(50Hz)的精密操作
π0 面临的具体需求
需求1:高频控制 → 需要50Hz的动作生成
需求2:精密操作 → 需要准确的连续动作分布
需求3:复杂任务 → 需要多模态动作分布(一个状态可能对应多种合理动作)
需求4:实时性能 → 推理速度要足够快
为什么选择流匹配而不是其他方法?
vs 扩散模型:流匹配收敛更快,推理步数更少
vs 自回归:流匹配能处理连续分布,精度更高
vs VAE/GAN:流匹配训练更稳定,生成质量更好
三、训练
3.1 数据准备与预处理

3.1.1. 数据收集策略
开源数据整合:约占数据集比例:9.1%
绝对规模:约 91M 时间步
数据来源:OXE、Bridge v2、DROID 等公开数据集
机器人覆盖:22 种不同机器人平台
作用——提供基础多样性:
环境覆盖:涵盖广泛的物体类型和操作环境
机器人多样性:22 种不同机器人配置带来的形态学多样性
任务基础:提供基本的抓取、放置、推拉等基础技能
技术特点与限制
控制频率:2-10Hz 的低频控制
传感器配置:通常只有 1-2 个摄像头
任务复杂度:相对简单的物体重定位和基础家具操作
预训练价值
跨域知识:提供不同实验室、不同设置下的机器人经验
泛化基础:帮助模型理解机器人操作的通用原理
数据补充:填补自收集数据可能存在的覆盖空白
自收集数据:约占比例:90.9%
绝对规模:903M 时间步(约为开源数据的 10 倍)
机器人分布:
单臂机器人:106M 时间步
双臂机器人:797M 时间步
任务覆盖:68 种复杂任务
作用
需要识别和分类各种物体(盘子、杯子、餐具、垃圾)
需要不同的抓取策略
需要放入正确的容器
实际行为范围远超 68 个"任务"数字所暗示的复杂度
传统定义:"拿起杯子" vs "拿起盘子" \= 2 个不同任务
π0 定义:"收拾桌子" \= 1 个任务(包含处理各种餐具、垃圾等)
高频控制:支持 50Hz 的精密操作
复杂任务:如折衣服、组装盒子等需要精细技巧的任务
多阶段行为:长时间序列的复杂操作链
提供精密操作能力
任务定义的革新
真实复杂度——以"bussing"(收拾桌子)任务为例:
3.1.2 预处理
动作空间标准化:所有机器人动作向量统一到 18 维(容纳最大配置)
配置空间对齐:关节角度向量同样统一到 18 维
缺失维度处理:低维机器人使用零填充,缺失摄像头用 mask 处理
权重策略:每个任务-机器人组合按$n^{0.43}$加权,其中 n 为样本数量
指数 \= 0: 完全平等采样 (每个任务权重相同) 指数 \= 0.43: 温和的规模惩罚 (π0 采用) 指数 \= 0.5: 平方根规模 (常见选择)
3.2 预训练过程(Pre-training)
3.2.1 模型初始化
VLM 骨干:从 PaliGemma-3B checkpoint 权重开始,继承互联网规模的视觉语言知识
Action Expert:从头初始化 300M 参数,专门学习机器人动作生成
输入输出层:新增的状态和动作投影层随机初始化
3.2.2. 预训练目标
广泛能力获取:在最大规模数据上学习通用机器人技能
跨任务泛化:发现不同任务间的共同模式和策略
错误恢复:从多样化数据中学习处理各种意外情况
零样本基础:建立基本的语言指令理解和执行能力
3.2.3. 损失函数设计
VLM 部分:继续使用交叉熵损失处理语言 token
Action Expert:使用流匹配损失处理动作 token
联合训练:两种损失同时优化,但路由到不同的权重组
3.3 后训练微调(Post-training)
3.3.1. 任务特定数据准备
高质量筛选:只保留展示最佳执行策略的轨迹
数据量调节:简单任务 5 小时,复杂任务 100+ 小时
关键 insight: π0 的强大预训练基础意味着你可以用远少于从零开始的数据量获得远好于预期的性能。如果是我们自己采集数据微调,建议先从小规模试验开始,根据实际效果决定是否需要更多数据!后文实操会具体介绍。
策略一致性:确保数据展示统一的解决方案
3.3.2. 微调策略
从预训练开始:利用预训练模型的广泛知识作为起点
保持恢复能力:不完全遗忘预训练的错误处理能力
专化执行:学习任务特定的精密操作技巧
效率优化:减少不必要的探索行为
3.3.3. 训练配方哲学
类似 LLM 的对齐过程:
预训练提供知识:广泛的技能和世界理解
后训练指导行为:如何优雅高效地使用这些知识
平衡多样性与质量:既能处理意外(预训练数据集包含了大量异常情况),又能流畅执行(微调的精细操作数据集)
四、推理流程
4.1 观察($o_t$)编码
多模态输入处理 $[I^1_t, I^2_t, I^3_t,\ell_t,q_t]$
图像获取:从 2-3 个摄像头获取 RGB 图像
语言解析:处理自然语言指令或任务描述
状态读取:获取当前机器人关节角度和姿态信息
特征提取
图像编码:预训练 ViT 编码器提取视觉特征
文本编码:利用 PaliGemma 的语言理解能力
状态嵌入:线性投影将关节状态映射到 transformer 空间
4.2 流匹配动作生成 Act Chunk
初始化
随机噪声:从标准高斯分布采样初始动作$A^0_t$
动作维度:生成 H\=50 步的未来动作序列
时间步设置:从$τ=0$开始,准备进行去噪过程
迭代去噪——重复 10 次积分步骤:
向量场预测:Action Expert 计算当前噪声状态下的去噪方向
积分更新:使用前向欧拉方法更新动作状态
步长控制:固定积分步长$δ=0.1$,确保稳定收敛
注意力计算:只重新计算动作 token 部分的 attention
收敛控制
固定步数:始终执行 10 步积分,不需要收敛判断
质量保证:充分的积分步数确保高质量动作生成
实时性考虑:平衡生成质量与推理速度
附录
附录一:VLM
VLM 指的是 Vision-Language Model(视觉语言模型) 。
1.1. 基本概念
VLM 是一种能够同时理解和处理**视觉信息(图像)和语言信息(文本)**的多模态 AI 模型。它可以:
理解图像内容并用自然语言描述
根据文本指令理解和分析图像
进行视觉问答、图像描述生成等任务
1.2. 在 π0 中的作用

π0 使用****(3B 参数)作为 VLM 骨干网络,PaliGemma = SigLIP图像编码器 + Gemma文本解码器 + 线性适配器
SigLIP-So400m:4 亿参数图像编码器,负责"看懂"图像Gemma-2B:20 亿参数文本解码器,负责"理解和生成"文字线性适配器:连接视觉和文本的桥梁
关键优势
结合了视觉理解和文本生成的双重能力
微调后可灵活适配各种下游任务
架构简洁高效(通过线性层连接两个强大组件)
在 π0 中的作用
PaliGemma 为 π0 提供了理解环境(视觉)和指令(语言)的基础能力,这正是机器人控制所需要的"感知 + 理解"核心功能。
继承了从大规模互联网数据中学到的语义知识
提供强大的视觉理解和语言理解能力
具体功能:
输入:机器人摄像头图像 + 自然语言指令
↓
VLM骨干网络处理
↓
输出:语义理解和特征表示
1.3 PaliGemma 能力示范
Image Captioning

Visual Question Answering

Detection

Segmentation

Document Understanding

附录三:范式 VS 技术
3.1 技术细节的局限性
π0 的具体架构选择:
PaliGemma 3B → 可能被 GPT-4V、Claude 等替代
Flow Matching → 可能被更好的生成方法超越
Action Expert → 可能有更优的融合方式
50Hz 控制频率 → 硬件进步会让这个数字过时
这些都会变,但范式不会!
3.2 范式的持久价值
π0 代表的范式转变:
大规模预训练 + 任务微调
跨模态统一建模(视觉 + 语言 + 动作)
跨实体知识共享
数据驱动的端到端学习
Foundation Model 思维
这些原则可能会指导未来 10 年的发展!
3.3. 范式引导资源配置
技术导向的资源配置:
70% 精力在算法优化
20% 精力在工程实现
10% 精力在数据收集
范式导向的资源配置:
70% 精力在数据获取和质量
20% 精力在训练基础设施
10% 精力在算法微调
π0 的成功很大程度上验证了后一种配置的正确性!
附录三:Diffusion policy
论文:
类似课程:
的
因为 diffusion 有很多变种,下面说的是常见的 DDPM(Denoising Diffusion Probabilistic Models)
首次将去噪扩散概率模型(DDPM)应用到机器人视觉运动策略学习中,其核心的扩散模型,最早用于图像生成(如 stable diffusion),DP 将策略表示为条件去噪扩散过程,通过迭代优化梯度场生成机器人行为。
我们先简单了解一下扩散模型,它主要分为两个过程。想象你在画一幅画:
加噪过程:就像往一幅清晰的画上逐渐撒灰尘,最后变成一团噪点
去噪过程:扩散模型学会了"逆向操作" - 从噪点中一步步恢复出原来的画
清晰图片 → 加噪 → 噪点
噪点 → 去噪 → 清晰图片
核心思想:扩散模型就是一个"聪明的橡皮擦",它学会了如何从随机噪声中"擦出"我们想要的东西!
正向过程 逆向过程 

配图来自课程。
3.1 逆向过程(生成)
目标:从噪声生成刘德华高清图
生成步骤:
步骤 1:噪声起点
输入:完全随机的噪声向量(高斯分布)
状态:什么都看不出,纯粹的噪点
无任何图片语义信息
步骤 2:第一次降噪
通过降噪模块处理一次
状态:噪声稍微减少,图片略微清晰
仍然看不出具体内容
步骤 3:持续降噪
再次通过降噪模块
状态:开始显现人物轮廓
能大致看出是个人形
步骤 4:反复迭代
重复执行降噪过程
状态:噪声逐步去除
图片越来越清晰
步骤 5:最终结果
完成所有降噪步骤
输出:刘德华的高清图片
完全恢复目标图像
核心原理
噪声 → 逐步去噪 → 清晰图片
每一步都让图片更接近我们想要的结果!
3.2 正向过程(加噪训练)
目标:将清晰图片逐步变成纯噪声
正向加噪步骤
步骤 1:选择训练图片
从训练集中随机选择一张清晰图片
例如:刘德华的高清照片
状态:完全清晰,细节丰富
步骤 2:第一次加噪
给原图添加少量高斯噪声
状态:图片稍微模糊,但仍能清楚识别
噪声强度:轻微
步骤 3:持续加噪
在已有噪声基础上继续添加噪声
状态:图片越来越模糊,细节逐渐丢失
噪声强度:逐步增加
步骤 4:反复迭代
重复执行加噪过程(通常几百到上千步,这也是扩散模型耗时的原因)
状态:图像信息不断被噪声掩盖
人物轮廓逐渐消失
步骤 5:完全噪声化
经过足够多的加噪步骤
状态:图片完全变成高斯分布的随机噪声
原始图像信息完全被掩盖
训练目标
每一步加噪后,训练降噪网络学会:
输入:当前噪声图片 + 噪声步数
输出:预测这一步添加的噪声是什么
学习:如何"反向去除"这些噪声
核心思想
清晰图片 → 逐步加噪 → 纯噪声
训练网络学会这个过程的逆向操作!
3.3 为什么能生成机器人动作?
动作也可以看作"图片"
# 传统思维:动作是数字
action = [x, y, z, 旋转...] # 几个数字
# 扩散模型思维:动作是"图案"
action_sequence = [
[x1, y1, z1], # 第1步
[x2, y2, z2], # 第2步
[x3, y3, z3], # 第3步
...
] # 这就像一个"动作图案"!
为什么像一个"动作图案"?——对于扩散模型来说,一切都是多维数组/矩阵。
传统的"图案"概念
首先看看我们熟悉的图片:
图片 = [
[红, 绿, 蓝, 红, ...], # 第1行像素
[蓝, 红, 绿, 蓝, ...], # 第2行像素
[绿, 蓝, 红, 绿, ...], # 第3行像素
...
]
每个位置的颜色值组合起来,形成我们看到的图案(比如一朵花、一只猫)。

动作序列也是"图案"!
现在看动作序列:
动作序列 = [ [向右移动, 稍微下降, 不旋转], # 第1秒动作 [继续右移, 快速下降, 轻微旋转], # 第2秒动作 [停止移动, 停止下降, 开始抓取], # 第3秒动作 ... ]
可以看到,他们的共性:
都有空间结构
图片的"空间": - 横轴:左右位置 - 纵轴:上下位置 - 值:颜色RGB 动作的"空间": - 横轴:时间(1秒,2秒,3秒...) - 纵轴:动作维度(x,y,z,旋转...) - 值:动作数值
都可以"画"出来!,把动作序列画成图:
时间 → 动 1秒 2秒 3秒 4秒 作 ┌────┬────┬────┬────┐ ↓ │ 0.1│ 0.3│ 0.5│ 0.2│ ← X方向 ├────┼────┼────┼────┤ │-0.2│-0.1│ 0.0│ 0.1│ ← Y方向 ├────┼────┼────┼────┤ │ 0.0│ 0.1│ 0.2│ 0.3│ ← Z方向 └────┴────┴────┴────┘
这不就是一个"图案"吗?!
举个例子,假设机器人要画一个圆,动作序列:
circle_action = [ [1.0, 0.0, 0.0], # 向右 [0.7, 0.7, 0.0], # 右上 [0.0, 1.0, 0.0], # 向上 [-0.7, 0.7, 0.0], # 左上 [-1.0, 0.0, 0.0], # 向左 [-0.7,-0.7, 0.0], # 左下 [0.0, -1.0, 0.0], # 向下 [0.7, -0.7, 0.0], # 右下 ]
如果把这个画出来:
X轴值 → 时 ┌─────────────────┐ 间 │ * * │ ↓ │ * * │ │ * * │ │* * │ │ * * │ │ * * │ │ * * │ └─────────────────┘
看!这就是一个圆形"图案"!
对扩散模型来说,这两个是一样的。
3.4 这样做有什么优势?
根据论文,扩散模型在机器人动作生成方面主要优势是良好的多模态动作分布:
多模态动作分布 (Multimodal Action Distributions)

什么是多模态?
场景:机器人要推T形积木到目标位置 传统方法的困扰: "我应该从左边推?还是右边推?" 只能选一种,经常选错或摇摆不定 扩散模型的智慧: "两种方法我都会!每次执行时我会选最合适的一种" 能表达所有可能的解决方案
短程多模态 vs 长程多模态
短程多模态 (Short-horizon Multimodality)
同一个目标的不同实现方式
例:绕过障碍物可以走左边或右边
长程多模态 (Long-horizon Multimodality)
不同子任务的执行顺序
例:厨房任务中先开水龙头还是先拿杯子
有时这里也称为多峰性 (Multi-peak) 。
高维输出空间处理 (High-dimensional Output Space)
传统方法的局限:
单步预测:只预测下一个动作 [动作1] → ? → [动作2] → ? → [动作3] 动作之间缺乏连贯性
扩散模型的优势:
序列预测:预测整个动作序列 (Action Sequence) [动作1 → 动作2 → 动作3 → ... → 动作N] 整体规划,动作连贯流畅
技术优势:
可扩展性 (Scalability):轻松处理高维动作空间
序列一致性 (Temporal Consistency):避免动作抖动
抗空闲动作 (Robustness to Idle Actions):不会卡在暂停状态
评论